模型训练的目的是使用生成的训练数据进行神经网络模型训练,根据设置参数,不断地对模型迭代评估,以得到可用的神经网络模型。
SuperMap 内置了 TensorFlow、Keras 等开源框架,结合不同的数据集类别对机器学习或深度学习模型进行训练,整体训练过程通过多次迭代(epoch)的方式来得到训练结果更优的网络模型,同时在训练模型中使用基于大规模基础训练数据的预训练模型,减少训练时间,通过超参数调优(学习率、Batchsize等)提升模型训练效率和准确度。桌面端训练工具适用于短周期模型训练。
目前 SuperMap 支持 U-Net 和 Faster R-CNN 等多种网络模型。
- U-Net:是一种全卷积网络,常见于图像分割任务,工作原理简单理解为先下采样,经过不同程度的卷积,学习了深层次的特征,在经过上采样回复为原图大小,上采样用反卷积实现。最后输出类别数量的特征图,如分割是两类(是或不是)。
- Faster R-CNN:常用于目标检测领域,工作原理简单理解为通过卷积层提取目标图片的特征,通过 RPN 网络(Region Proposal Network)输出推荐候选区域,然后进行分类和回归,输出候选区域所属的类和在图像的精确位置。
 主要参数
主要参数
- 功能入口 : 工具箱 -> 机器学习 -> 影像分析 -> 模型训练 工具。
- 训练数据路径 :选择通过 生成训练数据 工具的结果文件夹,即影像、标签训练数据所在文件夹。
- 训练数据用途 :选择使用模型的功能,提供了目标检测、二元分类、地物分类、场景分类四种用途。
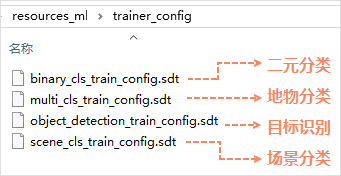
- 训练配置文件 :训练需要的算法配置文件(*.sdt),依据不同的模型用途和功能选择,该文件在环境配置文件夹 resourcesml/trainconfig 中。
- 训练次数 :所有训练数据参与模型训练的次数(epoch),随着训练次数的增多,模型拟合度越大,次数太多可能会出现过拟合的情况。默认值为 10,用户可根据需求选择,一般训练次数为 10-20 次,训练次数与运行花费时间成正比。
- 单步运算量 :一次训练中单步运算的图片数量(Batch Size)。多个图片组成的一份训练数据称之为一个 Batch,每个 Batch 所含的图片数量称为 Batch Size。在合理范围内,单步运算的数量与内存(显存)占用成正比,与训练时间成反比。默认值为 1,用户根据运行环境选择。
- 学习率 :模型参数的更新幅度(learning rate)。一般情况下,学习率需要根据经验设置,设置一个相对合适的值。学习率过大,会导致待优化参数在最小值附近进行波动;学习率过小,会导致待优化参数收敛的速度慢。默认值为 0.0001,目标检测一般为 0.001,二元分类一般为 0.0001。
- 训练日志路径 :用于设置训练日志存储路径,该路径下会生成多个文件夹,建议首次训练选择一个空文件夹。
- 加载预训练模型 :若勾选该选项,可选择前一次训练的训练日志路径作为预训练模型的路径,会在前一次的基础上进行训练。 注意 :前后两次训练需要训练数据的尺寸、类别和用途相同。
- 结果数据 :设置模型存储路径及模型名称。