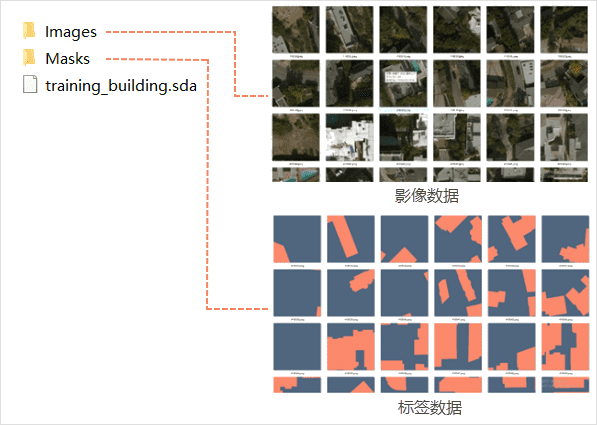
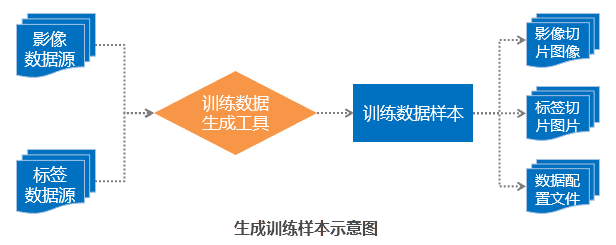
在没有模型的情况下,可通过训练数据生成工具,基于原始遥感影像数据和矢量标注数据,生成模型训练需要使用的训练数据。由于遥感影像数据体量较大,且卷积神经网络对于运行内存的要求较高,因此需要先把影像处理成适合机器学习模型训练的数据。训练数据生成工具的目的就是把影像数据和标签数据同步切分成一张张小图片和标签,生成适合神经网络模型训练的数据。
一般情况下,不同的训练数据(如分辨率,观测高度、观测角度、对象间距等)所获得的训练模型的准确度也有非常大的影响。所以对于训练样本数据来说,尽可能通过用户提供的基础数据来进行训练样本数据生成以及模型训练,可以尽可能保证模型的准确度。当用某一个特定的数据集训练模型时,我们需要确保模型训练基于整个数据集的分布。训练数据选择一般有以下要求:数据样本尽可能大、数据多样化,数据样本质量较高。
 数据准备
数据准备
在生成训练数据之前,需要准备的影像数据,以及希望识别的地物所在具体位置的标签数据。例如要做建筑物的识别,就需要目标区域的影像数据和建筑物矢量轮廓的标签数据,基于以上的样本数据生成相应格式的训练数据。
- 样本影像数据 :目标区域的影像数据,建议使用分辨率较高的航空影像片和卫星影像片。
- 样本标签数据 :矢量面数据集,面对象为影像数据中对象目标的外廓多边形对象,及相关的属性信息,例如目标识别(飞机),标注信息需要标识是否是飞机、该飞机的像素坐标、飞机型号等信息。

训练数据生成
主要操作步骤如下:
- 功能入口 : 工具箱 -> 机器学习 -> 影像分析 -> 生成训练数据 工具。
- 样本影像 :在 数据源 处选择以文件型数据源方式直接打开的影像数据,此时 数据集 会自动定位到数据源中的影像数据集。由于一般训练数据的影像文件尺度都较大,支持文件型影像数据,如 .tif、.img 等格式。
- 样本标签 :在 数据源 中选择标签数据集所在的数据源,并在数据集处选择标签面数据集。
- 图片大小 :设置将影像数据和标签数据划分为图片的行数和列数,单元为像元(Pixel),默认值为1024px,图片大小建议为 64 的整数倍,其大小与训练占用内存成正比,图片划分大小较小,则可减少计算机内存的消耗。
- 训练数据用途 :不同的训练数据用途使用的算法不同,根据用户用途而设定,提供了目标检测、二元分类、地物分类、场景分类四种用途。
-
类别字段 :设置标签数据中标识地物类型的字段。
- 目标检测:矢量标签中含有记录检测对象类别的字段,可加入类别字段中作为参考,若只有一类目标物可设置为空值。
- 二元分类:可设置为空值。
- 地物分类:需选择含有矢量标签的类别字段。
- 场景分类:需选择含有矢量标签的类别字段。
-
其他设置 :勾选该复选框,可对以下图片格式、偏移量、索引起始值参数进行设置。
- 图片格式:设置影像数据按照指定大小划分后的图像格式,提供与源数据相同、tiff、png、jpeg 四种图像格式。训练数据用途为目标检测时,图片仅支持 jpeg 格式。
- 垂直/水平偏移:为了扩充训练数据并保证每个标签都可以完整的参与训练而不被切分,图片需要重复切分,该值为重复切分时不同方向上偏移的大小,默认值为图片大小的一半。
- 索引起始值:系统会对切分生成的图片进行自然数顺序编码,默认从 00000000 开始,如用户需要进行特殊替换,则可自行设定起始值。默认值为 -1,表示如果选择的输出路径及数据名称文件夹下存在已经产生的训练数据,则默认向其中追加新生成的训练数据。若该值不为 -1,则在该文件夹下从设置的起始值开始生成数据,已有的同序号数据将被覆盖。
- 结果数据 :设置结果数据的输出路径,及结果数据的文件夹名称。结果数据包括影像数据和标签数据切分的图像,及数据的配置文件(*.sda)。 注意: 输出路径不能带中文字符。