- java.lang.Object
-
- com.supermap.analyst.terrainanalyst.HydrologyAnalyst
-
public class HydrologyAnalyst extends Object
水文分析类,用于填充洼地、流向分析、洼地计算、累积汇水量计算、流域计算、流长分析及矢量河网提取等水文分析功能,还提供网格剖分功能。水文分析基于数字高程模型(DEM)栅格数据建立水系模型,用于研究流域水文特征和模拟地表水文过程,并对未来的地表水文情况做出预估。水文分析模型能够帮助我们分析洪水的范围,定位径流污染源,预测地貌改变对径流的影响等,广泛应用于区域规划、农林、灾害预测、道路设计等诸多行业和领域。
地表水的汇流情况很大程度上决定于地表形状,而 DEM 数据能够表达区域地貌形态的空间分布,在描述流域地形,如流域边界、坡度和坡向、河网提取等方面具有突出优势,因而非常适用于水文分析。
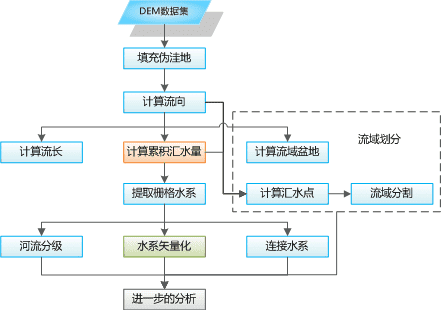
SuperMap 提供的水文分析主要内容有填充洼地、计算流向、计算流长、计算累积汇水量、流域划分、河流分级、连接水系及水系矢量化等。
- 水文分析的一般流程为:
- 如何获得栅格水系?
- 获得累积汇水量栅格,可通过
flowAccumulation方法实现。 - 通过 com.supermap.analyst.spatialanalyst 类的 execute(String, GeoRegion, PixelFormat, boolean, boolean, Datasource, String) 方法对累积汇水量栅格进行关系运算,就可以得到满足要求的栅格水系数据。假设设定阈值为 1000,则运算表达式为:"[Datasource.FlowAccumulationDataset]>1000"。除此,使用 Con(x,y,z) 函数也可以得到想要的结果,即表达式为:"Con([Datasource.FlowAccumulationDataset]>1000,1,0)"。
水文分析中很多功能都需要基于栅格水系数据,如提取矢量水系(
streamToLine方法)、河流分级(streamOrder方法)、连接水系(streamLink方法)等。通常,可以从累积汇水量栅格中提取栅格水系数据。在累积汇水量栅格中,单元格的值越大,代表该区域的累积汇水量越大。累积汇水量较高的单元格可视为河谷,因此,可以通过设定一个阈值,提取累积汇水量大于该值的单元格,这些单元格就构成栅格水系。值得说明的是,对于不同级别的河谷、不同区域的相同级别的河谷,该值可能不同,因此该阈值的确定需要依据研究区域的实际地形地貌并通过不断的试验来确定。
在 SuperMap 中,要求用于进一步分析(提取矢量水系、河流分级、连接水系等)的栅格水系为一个二值栅格,这可以通过栅格代数运算来实现,使大于或等于累积汇水量阈值的单元格为 1,否则为 0,如下图所示。
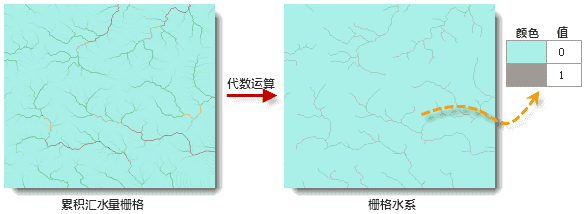
因此,提取栅格水系的过程如下:
-
-
方法概要
所有方法 静态方法 具体方法 已过时的方法 限定符和类型 方法和说明 static voidaddSteppedListener(SteppedListener l)添加一个进度条事件(SteppedEvent)的监听器。static DatasetGridbasin(DatasetGrid directionGrid, Datasource targetDatasource, String resultGridName)根据流向栅格计算流域盆地。static DatasetGridbasin(DatasetGrid directionGrid, Datasource targetDatasource, String resultGridName, SteppedListener... listeners)static GeoRegion[]buildQuadMesh(QuadMeshParameter quadMeshParameter)对单个简单面对象进行网格剖分,返回剖分后的简单面对象数组。static DatasetVectorbuildQuadMesh(QuadMeshParameter quadMeshParameter, Datasource targetDatasource, String resultGridName)对单个简单面对象进行网格剖分。static DatasetGridfillSink(DatasetGrid surfaceGrid, Datasource targetDatasource, String resultGridName)已过时。此方法已废弃,请使用支持进度监听的新方法HydrologyAnalyst.fillSink(DatasetGrid, Datasource, String, SteppedListener...)替换。static DatasetGridfillSink(DatasetGrid surfaceGrid, Datasource targetDatasource, String resultGridName, DatasetVector realSinkVector)根据已知的需要排除的洼地数据(点或面数据集)对 DEM 栅格数据填充伪洼地,在填洼结果栅格中这些洼地区域将被赋为无值。static DatasetGridfillSink(DatasetGrid surfaceGrid, Datasource targetDatasource, String resultGridName, DatasetVector realSinkVector, SteppedListener... listeners)static DatasetGridfillSink(DatasetGrid surfaceGrid, Datasource targetDatasource, String resultGridName, SteppedListener... listeners)对 DEM 栅格数据填充伪洼地。static DatasetGridflowAccumulation(DatasetGrid directionGrid, DatasetGrid weightGrid, Datasource targetDatasource, String resultGridName)根据流向栅格计算累积汇水量。static DatasetGridflowAccumulation(DatasetGrid directionGrid, DatasetGrid weightGrid, Datasource targetDatasource, String resultGridName, SteppedListener... listeners)static DatasetGridflowDirection(DatasetGrid surfaceGrid, boolean forceFlowAtEdge, Datasource targetDatasource, String resultGridName)已过时。此方法已废弃,请使用支持进度监听的新方法HydrologyAnalyst.flowDirection(DatasetGrid, boolean, Datasource, String, SteppedListener...)替换。static DatasetGridflowDirection(DatasetGrid surfaceGrid, boolean forceFlowAtEdge, Datasource targetDatasource, String resultGridName, SteppedListener... listeners)对 DEM 栅格数据计算流向。static DatasetGridflowDirection(DatasetGrid surfaceGrid, boolean forceFlowAtEdge, Datasource targetDatasource, String resultGridName, String dropGridName)对 DEM 栅格数据计算流向,并创建高程梯度栅格。static DatasetGridflowDirection(DatasetGrid surfaceGrid, boolean forceFlowAtEdge, Datasource targetDatasource, String resultGridName, String dropGridName, SteppedListener... listeners)static DatasetGridflowLength(DatasetGrid directionGrid, DatasetGrid weightGrid, boolean upStream, Datasource targetDatasource, String resultGridName)根据流向栅格计算流长,即计算每个单元格沿着流向到其流向起始点或终止点之间的距离。static DatasetGridflowLength(DatasetGrid directionGrid, DatasetGrid weightGrid, boolean upStream, Datasource targetDatasource, String resultGridName, SteppedListener... listeners)static DatasetVectorlongestFlowPath(DatasetGrid directionGrid, DatasetVector regionDataset, String regionIDField, Datasource targetDatasource, String resultDatasetName, SteppedListener... listeners)提取最长流路径,即提取指定区域面内流长最长的水系路径。static DatasetGridpourPoints(DatasetGrid directionGrid, DatasetGrid accumulationGrid, int areaLimit, Datasource targetDatasource, String resultGridName)根据流向栅格和累积汇水量栅格生成汇水点栅格。static DatasetGridpourPoints(DatasetGrid directionGrid, DatasetGrid accumulationGrid, int areaLimit, Datasource targetDatasource, String resultGridName, SteppedListener... listeners)static DatasetGridreconditionDEM(DatasetGrid surfaceGrid, DatasetVector streamDataset, double dropHeight, Datasource targetDatasource, String resultGridName, SteppedListener... listeners)static voidremoveSteppedListener(SteppedListener l)移除一个进度条事件(SteppedEvent)的监听器。static DatasetGridsnapPourPoint(Dataset pourPointDataset, DatasetGrid accumulationGrid, double snapDistance, String pourPointField, Datasource targetDatasource, String resultGridName)已过时。static DatasetGridsnapPourPoint(Dataset pourPointDataset, DatasetGrid accumulationGrid, double snapDistance, String pourPointField, Datasource targetDatasource, String resultGridName, SteppedListener... listeners)捕捉汇水点。static DatasetGridstreamLink(DatasetGrid streamGrid, DatasetGrid directionGrid, Datasource targetDatasource, String resultGridName)连接水系,即根据栅格水系和流向栅格为每条河流赋予唯一值。static DatasetGridstreamLink(DatasetGrid streamGrid, DatasetGrid directionGrid, Datasource targetDatasource, String resultGridName, SteppedListener... listeners)static DatasetGridstreamOrder(DatasetGrid streamGrid, DatasetGrid directionGrid, StreamOrderType orderType, Datasource targetDatasource, String resultGridName)对河流进行分级,根据河流等级为栅格水系编号。static DatasetGridstreamOrder(DatasetGrid streamGrid, DatasetGrid directionGrid, StreamOrderType orderType, Datasource targetDatasource, String resultGridName, SteppedListener... listeners)static DatasetVectorstreamToLine(DatasetGrid streamGrid, DatasetGrid directionGrid, Datasource targetDatasource, String resultDatasetName, StreamOrderType orderType)提取矢量水系,即将栅格水系转化为矢量水系。static DatasetVectorstreamToLine(DatasetGrid streamGrid, DatasetGrid directionGrid, Datasource targetDatasource, String resultDatasetName, StreamOrderType orderType, SteppedListener... listeners)static DatasetGridwatershed(DatasetGrid directionGrid, DatasetGrid pourPointsGrid, Datasource targetDatasource, String resultGridName)流域分割,即生成指定汇水点(汇水点栅格数据集)的流域盆地。static DatasetGridwatershed(DatasetGrid directionGrid, DatasetGrid pourPointsGrid, Datasource targetDatasource, String resultGridName, SteppedListener... listeners)static DatasetGridwatershed(DatasetGrid directionGrid, Point2Ds pourPoints, Datasource targetDatasource, String resultGridName)流域分割,即生成指定汇水点(二维点集合)的流域盆地。static DatasetGridwatershed(DatasetGrid directionGrid, Point2Ds pourPoints, Datasource targetDatasource, String resultGridName, SteppedListener... listeners)
-
-
-
方法详细资料
-
buildQuadMesh
public static GeoRegion[] buildQuadMesh(QuadMeshParameter quadMeshParameter)
对单个简单面对象进行网格剖分,返回剖分后的简单面对象数组。有关网格剖分的详细介绍,请参见
buildQuadMesh重载方法的相关介绍。注:
简单多边形:多边形内任何直线或边都不会交叉。
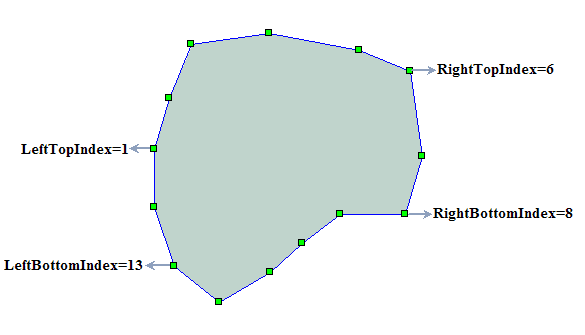
说明:RightTopIndex 为右上角点索引号,LeftTopIndex 为左上角点索引号,RightBottomIndex 为右下角点索引号,LeftBottomIndex 为左下角点索引号。则 nCount1=(RightTopIndex- LeftTopIndex+1)和 nCount2=(RightBottomIndex- LeftBottomIndex+1),如果:nCount1不等于nCount2,则程序不处理,返回的结果多边形为空。
- 参数:
quadMeshParameter- 网格剖分参数对象。- 返回:
- 剖分后的简单面对象数组。
-
buildQuadMesh
public static DatasetVector buildQuadMesh(QuadMeshParameter quadMeshParameter, Datasource targetDatasource, String resultGridName)
对单个简单面对象进行网格剖分。流体问题是一个连续性的问题,为了简化对其的研究以及建模处理的方便,对研究区域进行离散化处理,其思路就是建立离散的网格,网格划分就是对连续的物理区域进行剖分,把它分成若干个网格,并确定各个网格中的节点,用网格内的一个值来代替整个网格区域的基本情况,网格作为计算与分析的载体,其质量的好坏对后期的数值模拟的精度和计算效率有重要的影响。
网格剖分的步骤:
1.数据预处理,包含去除重复点等。给定一个合理的容限,去除重复点,使得最后的网格划分结果更趋合理,不会出现看起来从1个点(实际是重复点)出发有多条线的现象。
2.多边形分解:对于复杂的多边形区域,我们采用分块逐步划分的方法来进行网格的构建,将一个复杂的不规则多边形区域划分为多个简单的单连通区域,然后对每个单连通区域执行网格划分程序,最后再将各个子区域网格拼接起来构成对整个区域的划分。
3.选择四个角点:这4个角点对应着网格划分的计算区域上的4个顶点,其选择会对划分的结果造成影响。其选择应尽量在原区域近似四边形的四个顶点上,同时要考虑整体的流势。
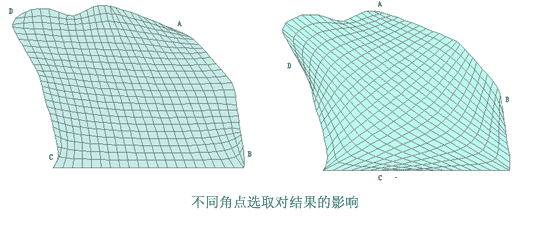
4.为了使划分的网格呈现四边形的特征,构成多边形的顶点数据(不在同一直线上)需参与构网。
5.进行简单区域网格划分。
注:
简单多边形:多边形内任何直线或边都不会交叉。
说明:RightTopIndex 为右上角点索引号,LeftTopIndex 为左上角点索引号,RightBottomIndex 为右下角点索引号,LeftBottomIndex 为左下角点索引号。则 nCount1=(RightTopIndex- LeftTopIndex+1)和 nCount2=(RightBottomIndex- LeftBottomIndex+1),如果:nCount1不等于nCount2,则程序不处理。
- 参数:
quadMeshParameter- 网格剖分参数对象。targetDatasource- 存放剖分结果数据集的数据源。resultGridName- 剖分结果数据集的名称。- 返回:
- 剖分后的结果数据集,剖分出的多个面以子对象形式返回。
-
reconditionDEM
public static DatasetGrid reconditionDEM(DatasetGrid surfaceGrid, DatasetVector streamDataset, double dropHeight, Datasource targetDatasource, String resultGridName, SteppedListener... listeners)
- 参数:
surfaceGrid- 原地形数据streamDataset- 河流线数据集dropHeight- 落差值,或刻入的深度,河流线所压盖的栅格高程值会减去这个值得到新的高程targetDatasource- 输出数据源resultGridName- 结果数据集名称- 返回:
- 返回刻入河流后的栅格地形数据。如果出错,返回null
-
fillSink
@Deprecated public static DatasetGrid fillSink(DatasetGrid surfaceGrid, Datasource targetDatasource, String resultGridName)
已过时。 此方法已废弃,请使用支持进度监听的新方法HydrologyAnalyst.fillSink(DatasetGrid, Datasource, String, SteppedListener...)替换。对 DEM 栅格数据填充伪洼地。洼地是指周围栅格都比其高的区域,分为自然洼地和伪洼地。
- 自然洼地,是实际存在的洼地,是地表真实形态的反映,如冰川或喀斯特地貌、采矿区、坑洞等,一般远少于伪洼地;
- 伪洼地,主要是由数据处理造成的误差、不合适的插值方法导致,在 DEM 栅格数据中很常见。
在确定流向时,由于洼地高程低于周围栅格的高程,一定区域内的流向都将指向洼地,导致水流在洼地聚集不能流出,引起汇水网络的中断,因此,填充洼地通常是进行合理流向计算的前提。
在填充某处洼地后,有可能产生新的洼地,因此,填充洼地是一个不断重复识别洼地、填充洼地的过程,直至所有洼地被填充且不再产生新的洼地。下图为填充洼地的剖面示意图。
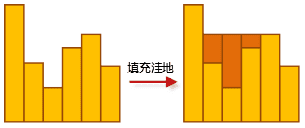
注意:
- 在填充伪洼地之前可以通过计算伪洼地,查看 DEM 数据中的洼地区域; 对于数据量较大或者洼地很多的 DEM,填充洼地所需要的时间可能较长。
注意,该方法会将 DEM 栅格中所有洼地填充,包括伪洼地和真实洼地。如果需要更精确的填充,可以使用另一个重载方法
fillSink,该方法可以指定已知的洼地,从而不对这些区域进行填充。- 参数:
surfaceGrid- 指定的要进行填充洼地的 DEM 数据。targetDatasource- 指定的用于存储结果数据集的数据源。如果设置为 null,则结果数据集将自动存储到 surfaceGrid 所在的数据源中。resultGridName- 指定的结果数据集的名称。- 返回:
- 无伪洼地的 DEM 栅格数据集。如果填充伪洼地失败,则返回 null。
-
fillSink
public static DatasetGrid fillSink(DatasetGrid surfaceGrid, Datasource targetDatasource, String resultGridName, SteppedListener... listeners)
对 DEM 栅格数据填充伪洼地。洼地是指周围栅格都比其高的区域,分为自然洼地和伪洼地。
- 自然洼地,是实际存在的洼地,是地表真实形态的反映,如冰川或喀斯特地貌、采矿区、坑洞等,一般远少于伪洼地;
- 伪洼地,主要是由数据处理造成的误差、不合适的插值方法导致,在 DEM 栅格数据中很常见。
在确定流向时,由于洼地高程低于周围栅格的高程,一定区域内的流向都将指向洼地,导致水流在洼地聚集不能流出,引起汇水网络的中断,因此,填充洼地通常是进行合理流向计算的前提。
在填充某处洼地后,有可能产生新的洼地,因此,填充洼地是一个不断重复识别洼地、填充洼地的过程,直至所有洼地被填充且不再产生新的洼地。下图为填充洼地的剖面示意图。
注意:
- 在填充伪洼地之前可以通过计算伪洼地,查看 DEM 数据中的洼地区域; 对于数据量较大或者洼地很多的 DEM,填充洼地所需要的时间可能较长。
注意,该方法会将 DEM 栅格中所有洼地填充,包括伪洼地和真实洼地。如果需要更精确的填充,可以使用另一个重载方法
fillSink,该方法可以指定已知的洼地,从而不对这些区域进行填充。- 参数:
surfaceGrid- 指定的要进行填充洼地的 DEM 数据。targetDatasource- 指定的用于存储结果数据集的数据源。如果设置为 null,则结果数据集将自动存储到 surfaceGrid 所在的数据源中。resultGridName- 指定的结果数据集的名称。listeners- 用于接收进度条事件的监听器。- 返回:
- 无伪洼地的 DEM 栅格数据集。如果填充伪洼地失败,则返回 null。
-
fillSink
public static DatasetGrid fillSink(DatasetGrid surfaceGrid, Datasource targetDatasource, String resultGridName, DatasetVector realSinkVector, SteppedListener... listeners)
- 参数:
surfaceGrid- 原地形数据targetDatasource- 输出数据源resultGridName- 结果数据集名称realSinkVector- 不需要填充的真实洼地,可以是点或面数据集- 返回:
- 返回没有伪洼地的栅格地形数据。如果出错,返回null
-
fillSink
public static DatasetGrid fillSink(DatasetGrid surfaceGrid, Datasource targetDatasource, String resultGridName, DatasetVector realSinkVector)
根据已知的需要排除的洼地数据(点或面数据集)对 DEM 栅格数据填充伪洼地,在填洼结果栅格中这些洼地区域将被赋为无值。该方法可以指定一个点或面数据集,用于指示的真实洼地或需排除的洼地,这些洼地不会被填充。使用准确的该类数据,将获得更为真实的无伪洼地地形,使后续分析更为可靠。
用于指示洼地的数据,如果是点数据集,其中的一个或多个点位于洼地内即可,最理想的情形是点指示该洼地区域的汇水点;如果是面数据集,每个面对象应覆盖一个洼地区域。
更多介绍请参见
fillSink重载方法。- 参数:
surfaceGrid- 指定的要进行填充伪洼地的原地形数据。targetDatasource- 指定的用于存储结果数据集的数据源。如果设置为 null,则结果数据集将自动存储到 surfaceGrid 所在的数据源中。resultGridName- 指定的结果数据集的名称。realSinkVector- 指定的用于指示已知自然洼地或要排除的洼地的点或面数据。如果是点数据集,一个或多个点所在的区域指示为洼地;如果是面数据集,每个面对象对应一个洼地区域。- 返回:
- 无伪洼地的 DEM 栅格数据集。如果填充伪洼地失败,则返回 null。
-
flowDirection
public static DatasetGrid flowDirection(DatasetGrid surfaceGrid, boolean forceFlowAtEdge, Datasource targetDatasource, String resultGridName, String dropGridName, SteppedListener... listeners)
- 参数:
surfaceGrid- 原地形数据forceFlowAtEdge- 是否令边界栅格的流向为向外targetDatasource- 输出数据源resultGridName- 结果数据集名称dropGridName- 高程梯度栅格数据集名称- 返回:
- 返回流向栅格。如果出错,返回null
-
flowDirection
public static DatasetGrid flowDirection(DatasetGrid surfaceGrid, boolean forceFlowAtEdge, Datasource targetDatasource, String resultGridName, String dropGridName)
对 DEM 栅格数据计算流向,并创建高程梯度栅格。为保证流向计算的正确性,建议使用填充伪洼地之后的 DEM 栅格数据。该方法可以创建用于计算流向的中间结果:高程梯度栅格。中心单元格与相邻单元格的高程差与距离的比值称为高程梯度。如下图所示,为流向计算的一个实例,该实例中生成了高程梯度栅格。更多介绍请参见
flowDirection方法。
- 参数:
surfaceGrid- 指定的用于计算流向的 DEM 数据。forceFlowAtEdge- 指定是否强制边界的栅格流向为向外。如果为 true,则 DEM 栅格边缘处的所有单元的流向都是从栅格向外流动。targetDatasource- 指定的用于存储结果数据集的数据源。如果设置为 null,则结果数据集将自动存储到 surfaceGrid 所在的数据源中。resultGridName- 指定的结果流向数据集的名称。dropGridName- 指定的高程梯度数据集的名称。- 返回:
- 结果流向栅格数据集。如果生成失败,则返回 null。
-
flowDirection
@Deprecated public static DatasetGrid flowDirection(DatasetGrid surfaceGrid, boolean forceFlowAtEdge, Datasource targetDatasource, String resultGridName)
已过时。 此方法已废弃,请使用支持进度监听的新方法HydrologyAnalyst.flowDirection(DatasetGrid, boolean, Datasource, String, SteppedListener...)替换。对 DEM 栅格数据计算流向。为保证流向计算的正确性,建议使用填充伪洼地之后的 DEM 栅格数据。流向,即水文表面水流的方向。计算流向是水文分析的关键步骤之一。水文分析的很多功能需要基于流向栅格,如计算累积汇水量、计算流长和流域等。
SuperMap 使用最大坡降法(D8,Deterministic Eight-node)计算流向。这种方法通过计算单元格的最陡下降方向作为水流的方向。中心单元格与相邻单元格的高程差与距离的比值称为高程梯度。最陡下降方向即为中心单元格与高程梯度最大的单元格所构成的方向,也就是中心栅格的流向。单元格的流向的值,是通过对其周围的8个邻域栅格进行编码来确定的。如下图所示,若中心单元格的水流方向是左边,则其水流方向被赋值16;若流向右边,则赋值1。
在 SuperMap 中,通过对中心栅格的 8 个邻域栅格编码(如下图所示),中心栅格的水流方向便可由其中的某一值来确定。例如,若中心栅格的水流方向是左边,则其水流方向被赋值 16;若流向右边,则赋值 1。
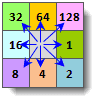
计算流向时,需要注意栅格边界单元格的处理。位于栅格边界的单元格比较特殊,通过 forceFlowAtEdge 参数可以指定其流向是否向外,如果向外,则边界栅格的流向值如下图(左)所示,否则,位于边界上的单元格将赋为无值,如下图(右)所示。
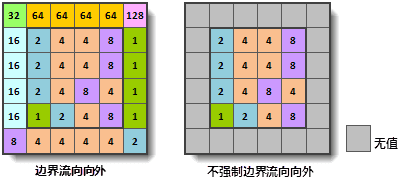
计算 DEM 数据每个栅格的流向得到流向栅格。下图显示了基于无洼地的 DEM 数据生成的流向栅格。
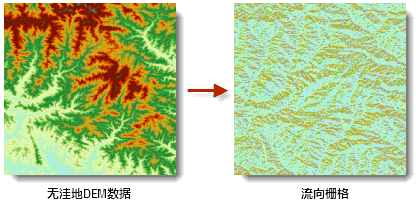
注:
使用另一重载方法
flowDirection可以创建高程梯度栅格。- 参数:
surfaceGrid- 指定的用于计算流向的 DEM 数据。forceFlowAtEdge- 指定是否强制边界的栅格流向为向外。如果为 true,则 DEM 栅格边缘处的所有单元的流向都是从栅格向外流动。targetDatasource- 指定的用于存储结果数据集的数据源。如果设置为 null,则结果数据集将自动存储到 surfaceGrid 所在的数据源中。resultGridName- 指定的结果流向数据集的名称。- 返回:
- 结果流向栅格数据集。如果生成失败,则返回 null。
-
flowDirection
public static DatasetGrid flowDirection(DatasetGrid surfaceGrid, boolean forceFlowAtEdge, Datasource targetDatasource, String resultGridName, SteppedListener... listeners)
对 DEM 栅格数据计算流向。为保证流向计算的正确性,建议使用填充伪洼地之后的 DEM 栅格数据。流向,即水文表面水流的方向。计算流向是水文分析的关键步骤之一。水文分析的很多功能需要基于流向栅格,如计算累积汇水量、计算流长和流域等。
SuperMap 使用最大坡降法(D8,Deterministic Eight-node)计算流向。这种方法通过计算单元格的最陡下降方向作为水流的方向。中心单元格与相邻单元格的高程差与距离的比值称为高程梯度。最陡下降方向即为中心单元格与高程梯度最大的单元格所构成的方向,也就是中心栅格的流向。单元格的流向的值,是通过对其周围的8个邻域栅格进行编码来确定的。如下图所示,若中心单元格的水流方向是左边,则其水流方向被赋值16;若流向右边,则赋值1。
在 SuperMap 中,通过对中心栅格的 8 个邻域栅格编码(如下图所示),中心栅格的水流方向便可由其中的某一值来确定。例如,若中心栅格的水流方向是左边,则其水流方向被赋值 16;若流向右边,则赋值 1。
计算流向时,需要注意栅格边界单元格的处理。位于栅格边界的单元格比较特殊,通过 forceFlowAtEdge 参数可以指定其流向是否向外,如果向外,则边界栅格的流向值如下图(左)所示,否则,位于边界上的单元格将赋为无值,如下图(右)所示。
计算 DEM 数据每个栅格的流向得到流向栅格。下图显示了基于无洼地的 DEM 数据生成的流向栅格。
注:
使用另一重载方法
flowDirection可以创建高程梯度栅格。- 参数:
surfaceGrid- 指定的用于计算流向的 DEM 数据。forceFlowAtEdge- 指定是否强制边界的栅格流向为向外。如果为 true,则 DEM 栅格边缘处的所有单元的流向都是从栅格向外流动。targetDatasource- 指定的用于存储结果数据集的数据源。如果设置为 null,则结果数据集将自动存储到 surfaceGrid 所在的数据源中。resultGridName- 指定的结果流向数据集的名称。listeners- 用于接收进度条事件的监听器。- 返回:
- 结果流向栅格数据集。如果生成失败,则返回 null。
-
flowAccumulation
public static DatasetGrid flowAccumulation(DatasetGrid directionGrid, DatasetGrid weightGrid, Datasource targetDatasource, String resultGridName, SteppedListener... listeners)
- 参数:
directionGrid- 流向栅格数据weightGrid- 权重栅格数据targetDatasource- 输出数据源resultGridName- 结果数据集名称- 返回:
- 返回伪洼地栅格。如果出错,返回null
-
flowAccumulation
public static DatasetGrid flowAccumulation(DatasetGrid directionGrid, DatasetGrid weightGrid, Datasource targetDatasource, String resultGridName)
根据流向栅格计算累积汇水量。可应用权重数据集计算加权累积汇水量。累积汇水量是指流向某个单元格的所有上游单元格的水流累积量,是基于流向数据计算得出的。
累积汇水量的值可以帮助我们识别河谷和分水岭。单元格的累积汇水量较高,说明该地地势较低,可视为河谷;为0说明该地地势较高,可能为分水岭。因此,累积汇水量是提取流域的各种特征参数(如流域面积、周长、排水密度等)的基础。
计算累积汇水量的基本思路是:假定栅格数据中的每个单元格处有一个单位的水量,依据水流方向图顺次计算每个单元格所能累积到的水量(不包括当前单元格的水量)。
下图显示了由水流方向计算累积汇水量的过程。
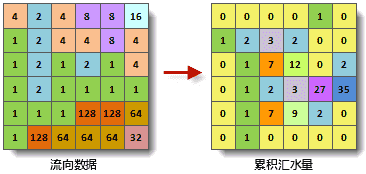
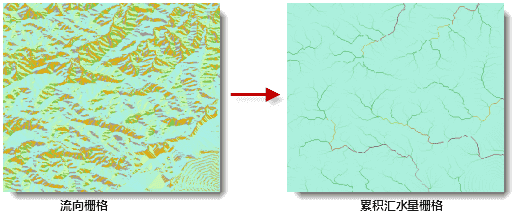
下图为流向栅格和基于其生成的累积汇水量栅格。
在实际应用中,每个单元格的水量不一定相同,往往需要指定权重数据来获取符合需求的累积汇水量。使用了权重数据后,累积汇水量的计算过程中,每个单元格的水量不再是一个单位,而是乘以权重(权重数据集的栅格值)后的值。例如,将某时期的平均降雨量作为权重数据,计算所得的累积汇水量就是该时期的流经每个单元格的雨量。
注意,权重栅格必须与流向栅格具有相同的范围和分辨率。
- 参数:
directionGrid- 指定的流向栅格数据。weightGrid- 指定的权重栅格数据。设置为 null 表示不使用权重数据集。targetDatasource- 指定的用于存储结果数据集的数据源。如果设置为 null,则结果数据集将自动存储到 directionGrid 所在的数据源中。resultGridName- 指定的结果数据集的名称。- 返回:
- 结果累积汇水量栅格数据集。如果生成失败,则返回 null。
-
flowLength
public static DatasetGrid flowLength(DatasetGrid directionGrid, DatasetGrid weightGrid, boolean upStream, Datasource targetDatasource, String resultGridName, SteppedListener... listeners)
- 参数:
directionGrid- 流向栅格数据weightGrid- 权重栅格数据upStream- true=溯流而上/false=顺流而下targetDatasource- 输出数据源resultGridName- 结果数据集名称- 返回:
- 返回流长图。如果出错,返回null
-
flowLength
public static DatasetGrid flowLength(DatasetGrid directionGrid, DatasetGrid weightGrid, boolean upStream, Datasource targetDatasource, String resultGridName)
根据流向栅格计算流长,即计算每个单元格沿着流向到其流向起始点或终止点之间的距离。可应用权重数据集计算加权流长。流长,是指每个单元格沿着流向到其流向起始点或终止点之间的距离,包括上游方向和下游方向的长度。水流长度直接影响地面径流的速度,进而影响地面土壤的侵蚀力,因此在水土保持方面具有重要意义,常作为土壤侵蚀、水土流失情况的评价因素。
流长的计算基于流向数据,流向数据表明水流的方向,该数据集可由流向分析创建;权重数据定义了每个单元格的水流阻力。流长一般用于洪水的计算,水流往往会受到诸如坡度、土壤饱和度、植被覆盖等许多因素的阻碍,此时对这些因素建模,需要提供权重数据集。
流长有两种计算方式:
- 顺流而下:计算每个单元格沿流向到下游流域汇水点之间的最长距离。
- 溯流而上:计算每个单元格沿流向到上游分水线顶点的最长距离。
下图分别为以顺流而下和溯流而上计算得出的流长栅格:

权重数据定义了每个栅格单元间的水流阻力,应用权重所获得的流长为加权距离(即距离乘以对应权重栅格的值)。例如,将流长分析应用于洪水的计算,洪水流往往会受到诸如坡度、土壤饱和度、植被覆盖等许多因素的阻碍,此时对这些因素建模,需要提供权重数据集。
注意,权重栅格必须与流向栅格具有相同的范围和分辨率。
- 参数:
directionGrid- 指定的流向栅格数据。weightGrid- 指定的权重栅格数据。设置为 null 表示不使用权重数据集。upStream- 指定顺流而下计算还是溯流而上计算。true 表示溯流而上,false 表示顺流而下。targetDatasource- 指定的用于存储结果数据集的数据源。如果设置为 null,则结果数据集将自动存储到 directionGrid 所在的数据源中。resultGridName- 指定的结果流长数据集的名称。- 返回:
- 结果流长栅格数据集。如果生成失败,则返回 null。
-
basin
public static DatasetGrid basin(DatasetGrid directionGrid, Datasource targetDatasource, String resultGridName, SteppedListener... listeners)
- 参数:
directionGrid- 流向栅格数据targetDatasource- 输出数据源resultGridName- 结果数据集名- 返回:
- 返回流域盆地图。如果出错,返回null
-
basin
public static DatasetGrid basin(DatasetGrid directionGrid, Datasource targetDatasource, String resultGridName)
根据流向栅格计算流域盆地。流域盆地即为集水区域,是用于描述流域的方式之一。
计算流域盆地是依据流向数据为每个单元格分配唯一盆地的过程,如下图所示,流域盆地是描述流域的方式之一,展现了那些所有相互连接且处于同一流域盆地的栅格。
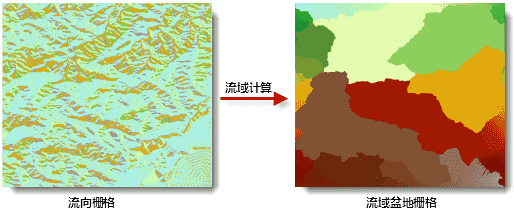
- 参数:
directionGrid- 指定的流向栅格数据集。targetDatasource- 指定的用于存储结果数据集的数据源。如果设置为 null,则结果数据集将自动存储到 directionGrid 所在的数据源中。resultGridName- 指定的结果数据集的名称。- 返回:
- 流域盆地栅格数据集。如果生成失败,则返回 null。
-
pourPoints
public static DatasetGrid pourPoints(DatasetGrid directionGrid, DatasetGrid accumulationGrid, int areaLimit, Datasource targetDatasource, String resultGridName, SteppedListener... listeners)
- 参数:
directionGrid- 流向栅格数据accumulationGrid- 累计汇水量栅格数据areaLimit- 汇水量限制targetDatasource- 输出数据源resultGridName- 结果数据集名称- 返回:
- 返回汇流点栅格数据。如果出错,返回null
-
pourPoints
public static DatasetGrid pourPoints(DatasetGrid directionGrid, DatasetGrid accumulationGrid, int areaLimit, Datasource targetDatasource, String resultGridName)
根据流向栅格和累积汇水量栅格生成汇水点栅格。汇水点位于流域的边界上,通常为边界上的最低点,流域内的水从汇水点流出,所以汇水点必定具有较高的累积汇水量。根据这一特点,就可以基于累积汇水量和流向栅格来提取汇水点。
汇水点的确定需要一个累积汇水量阈值,累积汇水量栅格中大于或等于该阈值的位置将作为潜在的汇水点,再依据流向最终确定汇水点的位置。该阈值的确定十分关键,影响着汇水点的数量、位置以及子流域的大小和范围等。合理的阈值,需要考虑流域范围内的土壤特征、坡度特征、气候条件等多方面因素,根据实际研究的需求来确定,因此具有较大难度。
获得了汇水点栅格后,可以结合流向栅格来进行流域的分割(
watershed方法)。- 参数:
directionGrid- 指定的流向栅格数据。accumulationGrid- 指定的累积汇水量栅格数据。areaLimit- 指定的汇水量限制值。targetDatasource- 指定的用于存储结果数据集的数据源。如果设置为 null,则结果数据集将自动存储到 directionGrid 所在的数据源中。resultGridName- 指定的结果栅格数据集的名称。- 返回:
- 结果汇水点栅格数据集。如果生成失败,则返回 null。
-
snapPourPoint
public static DatasetGrid snapPourPoint(Dataset pourPointDataset, DatasetGrid accumulationGrid, double snapDistance, String pourPointField, Datasource targetDatasource, String resultGridName, SteppedListener... listeners)
捕捉汇水点。将汇水点捕捉到指定范围内累积流量最大的像元,用于把汇水点数据纠正到河流上。汇水点一般可以用于桥梁、桥涵等水利设施的建设,但实际应用中汇水点不一定都是计算得到,即使用
pourPoints方法,可能通过其他方式,比如矢量地图中的位置转为栅格数据,这时便需要捕捉汇水点功能进行修正,确保累积汇水量最大。与获得汇水点栅格一样,捕捉汇水点后,可以进一步结合流向栅格来进行流域的分割(
watershed方法)。- 参数:
pourPointDataset- 指定的汇水点数据集,仅支持点数据集和栅格数据集。accumulationGrid- 累积汇水量栅格数据集。可通过(flowAccumulation方法)得到。snapDistance- 捕捉距离,捕捉汇水点到该范围内最大汇水量栅格位置上,该距离与指定的汇水点数据集单位一致。pourPointField- 用于为汇水点位置赋值的字段。当汇水点数据集为点数据集时,需指定汇水点栅格值字段。字段类型仅支持整型,如果非整型会强制转为整型。targetDatasource- 指定的用于存储结果数据集的数据源。如果设置为 null,则结果数据集将自动存储到汇水点数据集所在的数据源中。resultGridName- 指定的结果栅格数据集的名称。listeners- 用于接收进度条事件的监听器。- 返回:
- 结果汇水点的栅格数据集。如果生成失败,则返回 null。
-
snapPourPoint
@Deprecated public static DatasetGrid snapPourPoint(Dataset pourPointDataset, DatasetGrid accumulationGrid, double snapDistance, String pourPointField, Datasource targetDatasource, String resultGridName)
已过时。 此方法已废弃,请使用支持进度监听的新方法HydrologyAnalyst.snapPourPoint(Dataset, DatasetGrid, double, String, Datasource, String, SteppedListener...)替换。捕捉汇水点。将汇水点捕捉到指定范围内累积流量最大的像元,用于把汇水点数据纠正到河流上。汇水点一般可以用于桥梁、桥涵等水利设施的建设,但实际应用中汇水点不一定都是计算得到,即使用
pourPoints方法,可能通过其他方式,比如矢量地图中的位置转为栅格数据,这时便需要捕捉汇水点功能进行修正,确保累积汇水量最大。与获得汇水点栅格一样,捕捉汇水点后,可以进一步结合流向栅格来进行流域的分割(
watershed方法)。- 参数:
pourPointDataset- 指定的汇水点数据集,仅支持点数据集和栅格数据集。accumulationGrid- 累积汇水量栅格数据集。可通过(flowAccumulation方法)得到。snapDistance- 捕捉距离,捕捉汇水点到该范围内最大汇水量栅格位置上,该距离与指定的汇水点数据集单位一致。pourPointField- 用于为汇水点位置赋值的字段。当汇水点数据集为点数据集时,需指定汇水点栅格值字段。字段类型仅支持整型,如果非整型会强制转为整型。targetDatasource- 指定的用于存储结果数据集的数据源。如果设置为 null,则结果数据集将自动存储到汇水点数据集所在的数据源中。resultGridName- 指定的结果栅格数据集的名称。- 返回:
- 结果汇水点的栅格数据集。如果生成失败,则返回 null。
-
watershed
public static DatasetGrid watershed(DatasetGrid directionGrid, Point2Ds pourPoints, Datasource targetDatasource, String resultGridName, SteppedListener... listeners)
- 参数:
directionGrid- 流向栅格数据pourPoints- 指定的汇流点,地理坐标targetDatasource- 输出数据源resultGridName- 结果数据集名称- 返回:
- 返回汇水口的流域盆地图。如果出错,返回null
-
watershed
public static DatasetGrid watershed(DatasetGrid directionGrid, Point2Ds pourPoints, Datasource targetDatasource, String resultGridName)
流域分割,即生成指定汇水点(二维点集合)的流域盆地。该方法通过指定一个代表汇水点位置的二维点集合来分割流域。更多内容请参见
watershed方法。- 参数:
directionGrid- 指定的流向栅格数据。pourPoints- 指定的汇水点,使用地理坐标单位。targetDatasource- 指定的用于存储结果数据集的数据源。如果设置为 null,则结果数据集将自动存储到 directionGrid 所在的数据源中。resultGridName- 指定的结果栅格数据集的名称。- 返回:
- 指定汇水点的流域盆地栅格数据集。如果生成失败,则返回 null。
-
watershed
public static DatasetGrid watershed(DatasetGrid directionGrid, DatasetGrid pourPointsGrid, Datasource targetDatasource, String resultGridName, SteppedListener... listeners)
- 参数:
directionGrid- 流向栅格数据pourPointsGrid- 指定的汇流点栅格数据targetDatasource- 输出数据源resultGridName- 结果数据集名称- 返回:
- 返回汇水口的流域盆地图。如果出错,返回null
-
watershed
public static DatasetGrid watershed(DatasetGrid directionGrid, DatasetGrid pourPointsGrid, Datasource targetDatasource, String resultGridName)
流域分割,即生成指定汇水点(汇水点栅格数据集)的流域盆地。将一个流域划分为若干个子流域的过程称为流域分割。通过
basin方法,可以获取较大的流域,但实际分析中,可能需要将较大的流域划分出更小的流域(称为子流域)。确定流域的第一步是确定该流域的汇水点,那么,流域分割同样首先要确定子流域的汇水点。与使用 basin 方法计算流域盆地不同,子流域的汇水点可以在栅格的边界上,也可能位于栅格的内部。该方法要求输入一个汇水点栅格数据,该数据可通过提取汇水点功能(
pourPoints方法)获得。此外,还可以使用另一个重载方法,输入表示汇水点的二维点集合来分割流域。- 参数:
directionGrid- 指定的流向栅格数据。pourPointsGrid- 指定的汇水点栅格数据。targetDatasource- 指定的用于存储结果数据集的数据源。如果设置为 null,则结果数据集将自动存储到 directionGrid 所在的数据源中。resultGridName- 指定的结果栅格数据集的名称。- 返回:
- 指定汇水点的流域盆地栅格数据集。如果生成失败,则返回 null。
-
streamToLine
public static DatasetVector streamToLine(DatasetGrid streamGrid, DatasetGrid directionGrid, Datasource targetDatasource, String resultDatasetName, StreamOrderType orderType, SteppedListener... listeners)
- 参数:
streamGrid- 栅格水系directionGrid- 流向栅格数据targetDatasource- 输出数据源resultDatasetName- 结果数据集名称- 返回:
- 返回矢量水系线数据集。如果出错,返回null
-
streamToLine
public static DatasetVector streamToLine(DatasetGrid streamGrid, DatasetGrid directionGrid, Datasource targetDatasource, String resultDatasetName, StreamOrderType orderType)
提取矢量水系,即将栅格水系转化为矢量水系。提取矢量水系是基于流向栅格,将栅格水系转化为矢量水系(一个矢量线数据集)的过程。得到矢量水系后,就可以进行各种基于矢量的计算、处理和空间分析,如构建水系网络。下图为 DEM 数据以及对应的矢量水系。
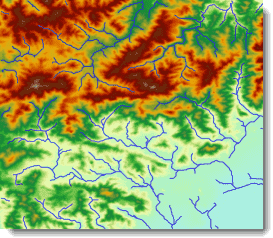
通过该方法获得的矢量水系数据集,保留了河流的等级和流向信息。
- 在提取矢量水系的同时,系统计算每条河流的等级,并在结果数据集中自动添加一个名为“StreamOrder”的属性字段来存储该值。分级的方式可通过 orderType 参数设置。
- 流向信息存储在结果数据集中名为“Direction”的字段中,以0或1来表示,0表示流向与该线对象的几何方向一致,1表示与线对象的几何方向相反。通过该方法获得的矢量水系的流向均与其几何方向相同,即“Direction”字段值都为0。在对矢量水系构建水系网络后,可直接使用(或根据实际需要进行修改)该字段作为流向字段。
- 参数:
streamGrid- 指定的栅格水系数据。directionGrid- 指定的流向栅格数据。targetDatasource- 指定的用于存储结果数据集的数据源。如果设置为 null,则结果数据集将自动存储到 directionGrid 所在的数据源中。resultDatasetName- 指定的结果栅格数据集的名称。orderType- 指定的河流分级方法。- 返回:
- 矢量水系数据集,为一个矢量线数据集。如果生成失败,则返回 null。
-
streamLink
public static DatasetGrid streamLink(DatasetGrid streamGrid, DatasetGrid directionGrid, Datasource targetDatasource, String resultGridName, SteppedListener... listeners)
- 参数:
streamGrid- 栅格水系directionGrid- 流向栅格数据targetDatasource- 输出数据源resultGridName- 结果数据集名称- 返回:
- 返回分段栅格水系网络图。如果出错,返回null
-
streamLink
public static DatasetGrid streamLink(DatasetGrid streamGrid, DatasetGrid directionGrid, Datasource targetDatasource, String resultGridName)
连接水系,即根据栅格水系和流向栅格为每条河流赋予唯一值。连接水系基于栅格水系和流向栅格,为水系中的每条河流分别赋予唯一值,值为整型。连接后的水系网络记录了水系节点的连接信息,体现了水系的网络结构。
如下图所示,连接水系后,每条河段都有唯一的栅格值。图中红色的点为交汇点,即河段与河段相交的位置。河段是河流的一部分,它连接两个相邻交汇点,或连接一个交汇点和汇水点,或连接一个交汇点和分水线。因此,连接水系可用于确定流域盆地的汇水点。
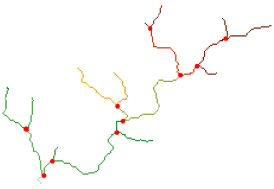
下图连接水系的一个实例。
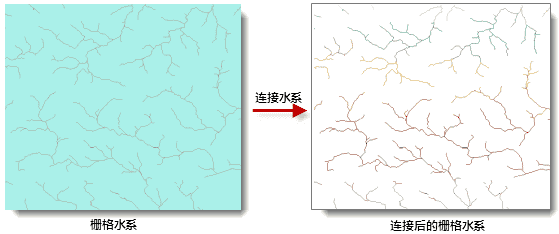
- 参数:
streamGrid- 指定的栅格水系数据。directionGrid- 指定的流向栅格数据。targetDatasource- 指定的用于存储结果数据集的数据源。如果设置为 null,则结果数据集将自动存储到 directionGrid 所在的数据源中。resultGridName- 指定的结果栅格数据集的名称。- 返回:
- 连接后的栅格水系,为一个栅格数据集。如果连接水系失败,则返回 null。
-
streamOrder
public static DatasetGrid streamOrder(DatasetGrid streamGrid, DatasetGrid directionGrid, StreamOrderType orderType, Datasource targetDatasource, String resultGridName, SteppedListener... listeners)
- 参数:
streamGrid- 栅格水系directionGrid- 流向栅格数据orderType- 编号方法targetDatasource- 输出数据源resultGridName- 结果数据集名称- 返回:
- 返回编号后的栅格水系网络图。如果出错,返回null
-
streamOrder
public static DatasetGrid streamOrder(DatasetGrid streamGrid, DatasetGrid directionGrid, StreamOrderType orderType, Datasource targetDatasource, String resultGridName)
对河流进行分级,根据河流等级为栅格水系编号。流域中的河流分为干流和支流,在水文学中,根据河流的流量、形态等因素对河流进行分级。在水文分析中,可以从河流的级别推断出河流的某些特征。
该方法以栅格水系为基础,依据流向栅格对河流分级,结果栅格的值即代表该条河流的等级,值越大,等级越高。SuperMap 提供两种河流分级方法:Strahler 法和 Shreve 法。有关这两种方法的介绍请参见
StreamOrderType枚举类型。如下图所示,是河流分级的一个实例。根据 Shreve 河流分级法,该区域的河流被分为14个等级。

- 参数:
streamGrid- 指定的栅格水系数据。directionGrid- 指定的流向栅格数据。orderType- 指定的流域水系编号方法。targetDatasource- 指定的用于存储结果数据集的数据源。如果设置为 null,则结果数据集将自动存储到 directionGrid 所在的数据源中。resultGridName- 指定的结果栅格数据集的名称。- 返回:
- 编号后的栅格流域水系网络,为一个栅格数据集。如果编号失败,则返回 null。
-
longestFlowPath
public static DatasetVector longestFlowPath(DatasetGrid directionGrid, DatasetVector regionDataset, String regionIDField, Datasource targetDatasource, String resultDatasetName, SteppedListener... listeners)
提取最长流路径,即提取指定区域面内流长最长的水系路径。该功能通过输入八方向流向栅格数据集和区域面数据集,追溯最长流路径,得到每个区域内的最长的一根无分支的水系线。
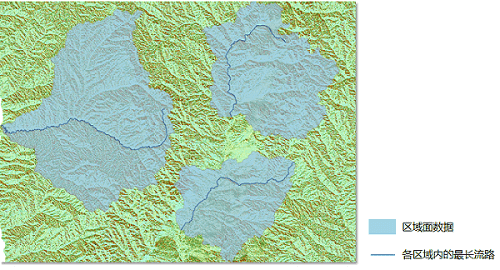
- 参数:
directionGrid- 指定的流向栅格数据集。regionDataset- 指定的集水区域面数据集。regionIDField- 集水区域面ID字段名,可设置为SmID。targetDatasource- 指定的用于存储结果数据集的数据源。resultDatasetName- 指定的结果水系线数据集名称。listeners- 用于接收进度条事件的监听器。- 返回:
- 返回矢量水系线数据集。如果出错,返回null。结果线数据集中将创建“CatchmentID”字段,使水系线能与区域面对象一一对应。
-
addSteppedListener
public static void addSteppedListener(SteppedListener l)
添加一个进度条事件(SteppedEvent)的监听器。- 参数:
l- 一个用于接收进度条事件的监听器。
-
removeSteppedListener
public static void removeSteppedListener(SteppedListener l)
移除一个进度条事件(SteppedEvent)的监听器。- 参数:
l- 一个用于接收进度条事件的监听器。
-
-