- java.lang.Object
-
- com.supermap.analyst.spatialstatistics.ClusteringDistributions
-
public class ClusteringDistributions extends Object
聚类分布类。该类可识别一组数据具有统计显著性的热点、冷点或者空间异常值。聚类分布用来计算的数据可以是点、线、面。对于点、线和面对象,在距离计算中会使用对象的质心。对象的质心为所有子对象的加权平均中心。点对象的加权项为1(即质心为自身),线对象的加权项是长度,而面对象的加权项是面积。
用户可以通过聚类分布计算来解决以下问题:
1. 聚类或冷点和热点出现在哪里?
2. 空间异常值的出现位置在哪里?
3. 哪些要素十分相似?
-
-
方法概要
所有方法 静态方法 具体方法 已过时的方法 限定符和类型 方法和说明 static voidaddSteppedListener(SteppedListener l)添加一个进度条事件(SteppedEvent)的监听器。static DatasetVectorclusterOutlierAnalyst(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, PatternsParameter patternsParameter)已过时。static DatasetVectorclusterOutlierAnalyst(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, PatternsParameter patternsParameter, SteppedListener... listeners)聚类和异常值分析,返回结果矢量数据集。static DatasetVectordensityBasedClustering(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, int minPilePointCount, double searchDistance, Unit unit)已过时。static DatasetVectordensityBasedClustering(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, int minPilePointCount, double searchDistance, Unit unit, SteppedListener... listeners)密度聚类分析static DatasetVectorhierarchicalDensityBasedClustering(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, int minPilePointCount)已过时。static DatasetVectorhierarchicalDensityBasedClustering(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, int minPilePointCount, SteppedListener... listeners)层次密度聚类分析static DatasetVectorhotSpotAnalyst(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, PatternsParameter patternsParameter)已过时。static DatasetVectorhotSpotAnalyst(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, PatternsParameter patternsParameter, SteppedListener... listeners)热点分析,返回结果矢量数据集。static DatasetVectorkmeans(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, KMeansParameter parameter, SteppedListener... listeners)K均值聚类,返回聚类中心矢量点结果数据集。static Point2D[]kmeans(DatasetVector sourceDatasetVector, KMeansParameter parameter, SteppedListener... listeners)K均值聚类,返回聚类中心二维点数组。static DatasetVectormeanShift(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, MeanShiftParameter parameter, SteppedListener... listeners)均值偏移聚类,返回聚类中心矢量点结果数据集。static Point2D[]meanShift(DatasetVector sourceDatasetVector, MeanShiftParameter parameter, SteppedListener... listeners)均值偏移聚类,返回聚类中心二维点数组。static DatasetVectoroptimizedHotSpotAnalyst(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, OptimizedParameter optimizedParameter)static DatasetVectoroptimizedHotSpotAnalyst(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, OptimizedParameter optimizedParameter, SteppedListener... listeners)优化的热点分析,返回结果矢量数据集。static DatasetVectororderingDensityBasedClustering(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, int minPilePointCount, double searchDistance, Unit unit, int clusterSensitivity)static DatasetVectororderingDensityBasedClustering(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, int minPilePointCount, double searchDistance, Unit unit, int clusterSensitivity, SteppedListener... listeners)顺序密度聚类分析static voidremoveSteppedListener(SteppedListener l)移除一个进度条事件(SteppedEvent)的监听器。
-
-
-
方法详细资料
-
hotSpotAnalyst
@Deprecated public static DatasetVector hotSpotAnalyst(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, PatternsParameter patternsParameter)
已过时。 此方法已废弃,请使用支持进度监听的新方法ClusteringDistributions.hotSpotAnalyst(DatasetVector, Datasource, String, PatternsParameter, SteppedListener...)替换。热点分析,返回结果矢量数据集。1. 结果数据集中包括z得分(Gi_Zscore)、P值(Gi_Pvalue)和置信区间(Gi_ConfInvl)。
2. z得分和P值都是统计显著性的度量,用于逐要素的判断是否拒绝"零假设"。置信区间字段会识别具有统计显著性的热点和冷点。置信区间为+3和-3的要素反映置信度为99%的统计显著性,置信区间为+2和-2的要素反映置信度为95%的统计显著性,置信区间为+1和-1的要素反映置信度为90%的统计显著性,而置信区间为0的要素的聚类则没有统计意义。
3. 在没有设置
PatternsParameter.setFDRAdjusted方法的情况下,统计显著性以P值和Z字段为基础,否则,确定置信度的关键P值会降低以兼顾多重测试和空间依赖性。4. 调用该方法时,需要通过 patternsParameter 参数指定一个分析模式参数(
PatternsParameter)对象,该对象用于热点分析所需的参数,如评估字段、概念化模型、距离容限等。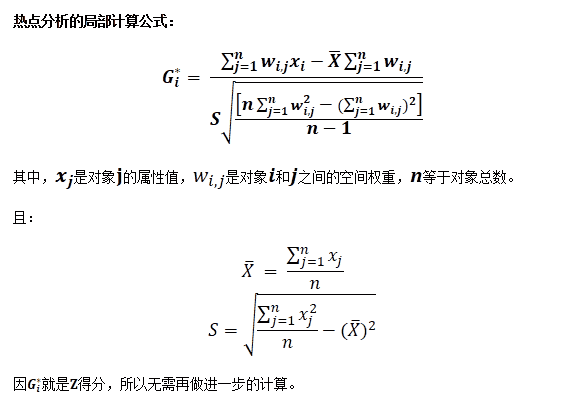
- 参数:
sourceDatasetVector- 指定的待计算的数据集。可以为点、线、面数据集。targetDatasource- 指定的用于存储结果数据集的数据源。targetDatasetName- 指定的结果数据集名称。patternsParameter- 指定的聚类分布参数设置。- 返回:
- 结果矢量数据集。
-
hotSpotAnalyst
public static DatasetVector hotSpotAnalyst(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, PatternsParameter patternsParameter, SteppedListener... listeners)
热点分析,返回结果矢量数据集。1. 结果数据集中包括z得分(Gi_Zscore)、P值(Gi_Pvalue)和置信区间(Gi_ConfInvl)。
2. z得分和P值都是统计显著性的度量,用于逐要素的判断是否拒绝"零假设"。置信区间字段会识别具有统计显著性的热点和冷点。置信区间为+3和-3的要素反映置信度为99%的统计显著性,置信区间为+2和-2的要素反映置信度为95%的统计显著性,置信区间为+1和-1的要素反映置信度为90%的统计显著性,而置信区间为0的要素的聚类则没有统计意义。
3. 在没有设置
PatternsParameter.setFDRAdjusted方法的情况下,统计显著性以P值和Z字段为基础,否则,确定置信度的关键P值会降低以兼顾多重测试和空间依赖性。4. 调用该方法时,需要通过 patternsParameter 参数指定一个分析模式参数(
PatternsParameter)对象,该对象用于热点分析所需的参数,如评估字段、概念化模型、距离容限等。- 参数:
sourceDatasetVector- 指定的待计算的数据集。可以为点、线、面数据集。targetDatasource- 指定的用于存储结果数据集的数据源。targetDatasetName- 指定的结果数据集名称。patternsParameter- 指定的聚类分布参数设置。listeners- 用于接收进度条事件的监听器。- 返回:
- 结果矢量数据集。
-
clusterOutlierAnalyst
@Deprecated public static DatasetVector clusterOutlierAnalyst(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, PatternsParameter patternsParameter)
已过时。 此方法已废弃,请使用支持进度监听的新方法ClusteringDistributions.clusterOutlierAnalyst(DatasetVector, Datasource, String, PatternsParameter, SteppedListener...)替换。聚类和异常值分析,返回结果矢量数据集。1. 结果数据集中包括局部莫兰指数(ALMI_MoranI)、z得分(ALMI_Zscore)、P值(ALMI_Pvalue)和聚类和异常值类型(ALMI_Type)。
2. z得分和P值都是统计显著性的度量,用于逐要素的判断是否拒绝"零假设"。置信区间字段会识别具有统计显著性的聚类和异常值。如果,要素的Z得分是一个较高的正值,则表示周围的要素拥有相似值(高值或低值),聚类和异常值类型字段将具有统计显著性的高值聚类表示为"HH",将具有统计显著性的低值聚类表示为"LL";如果,要素的Z得分是一个较低的负值值,则表示有一个具有统计显著性的空间数据异常值,聚类和异常值类型字段将指出低值要素围绕高值要素表示为"HL",将高值要素围绕低值要素表示为"LH"。
3. 在没有设置
PatternsParameter.setFDRAdjusted方法的情况下,统计显著性以P值和Z字段为基础,否则,确定置信度的关键P值会降低以兼顾多重测试和空间依赖性。4. 调用该方法时,需要通过 patternsParameter 参数指定一个分析模式参数(
PatternsParameter)对象,该对象用于聚类和异常值分析所需的参数,如评估字段、概念化模型、距离容限等。
- 参数:
sourceDatasetVector- 指定的待计算的数据集。可以为点、线、面数据集。targetDatasource- 指定的用于存储结果数据集的数据源。targetDatasetName- 指定的结果数据集名称。patternsParameter- 指定的聚类分布参数设置。- 返回:
- 结果矢量数据集。
-
clusterOutlierAnalyst
public static DatasetVector clusterOutlierAnalyst(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, PatternsParameter patternsParameter, SteppedListener... listeners)
聚类和异常值分析,返回结果矢量数据集。1. 结果数据集中包括局部莫兰指数(ALMI_MoranI)、z得分(ALMI_Zscore)、P值(ALMI_Pvalue)和聚类和异常值类型(ALMI_Type)。
2. z得分和P值都是统计显著性的度量,用于逐要素的判断是否拒绝"零假设"。置信区间字段会识别具有统计显著性的聚类和异常值。如果,要素的Z得分是一个较高的正值,则表示周围的要素拥有相似值(高值或低值),聚类和异常值类型字段将具有统计显著性的高值聚类表示为"HH",将具有统计显著性的低值聚类表示为"LL";如果,要素的Z得分是一个较低的负值值,则表示有一个具有统计显著性的空间数据异常值,聚类和异常值类型字段将指出低值要素围绕高值要素表示为"HL",将高值要素围绕低值要素表示为"LH"。
3. 在没有设置
PatternsParameter.setFDRAdjusted方法的情况下,统计显著性以P值和Z字段为基础,否则,确定置信度的关键P值会降低以兼顾多重测试和空间依赖性。4. 调用该方法时,需要通过 patternsParameter 参数指定一个分析模式参数(
PatternsParameter)对象,该对象用于聚类和异常值分析所需的参数,如评估字段、概念化模型、距离容限等。- 参数:
sourceDatasetVector- 指定的待计算的数据集。可以为点、线、面数据集。targetDatasource- 指定的用于存储结果数据集的数据源。targetDatasetName- 指定的结果数据集名称。patternsParameter- 指定的聚类分布参数设置。listeners- 用于接收进度条事件的监听器。- 返回:
- 结果矢量数据集。
-
optimizedHotSpotAnalyst
@Deprecated public static DatasetVector optimizedHotSpotAnalyst(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, OptimizedParameter optimizedParameter)
已过时。 此方法已废弃,请使用支持进度监听的新方法ClusteringDistributions.optimizedHotSpotAnalyst(DatasetVector, Datasource, String, OptimizedParameter, SteppedListener...)替换。优化的热点分析,返回结果矢量数据集。1. 结果数据集中包括z得分(Gi_Zscore)、P值(Gi_Pvalue)和置信区间(Gi_ConfInvl),详细介绍请参阅
hotSpotAnalyst方法结果。2. z得分和P值都是统计显著性的度量,用于逐要素的判断是否拒绝"零假设"。置信区间字段会识别具有统计显著性的热点和冷点。置信区间为+3和-3的要素反映置信度为99%的统计显著性,置信区间为+2和-2的要素反映置信度为95%的统计显著性,置信区间为+1和-1的要素反映置信度为90%的统计显著性,而置信区间为0的要素的聚类则没有统计意义。
3. 如果提供分析字段,则会直接执行热点分析; 如果未提供分析字段,则会利用提供的聚合方法(参阅
AggregationMethod)聚合所有输入事件点以获得计数,从而作为分析字段执行热点分析。4. 执行热点分析时,默认概念化模型为
ConceptualizationModel.FIXEDDISTANCEBAND、错误发现率(FDR)为 true ,统计显著性将使用错误发现率(FDR)校正法自动兼顾多重测试和空间依赖性。5. 调用该方法时,需要通过 optimizedParameter 参数指定一个分析模式参数(
OptimizedParameter)对象,该对象用于热点分析所需的参数,如评估字段、聚合方法等。
- 参数:
sourceDatasetVector- 指定的待计算的数据集。可以为点、线、面数据集。targetDatasource- 指定的用于存储结果数据集的数据源。targetDatasetName- 指定的结果数据集名称。optimizedParameter- 指定的优化的热点分析参数设置。
-
optimizedHotSpotAnalyst
public static DatasetVector optimizedHotSpotAnalyst(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, OptimizedParameter optimizedParameter, SteppedListener... listeners)
优化的热点分析,返回结果矢量数据集。1. 结果数据集中包括z得分(Gi_Zscore)、P值(Gi_Pvalue)和置信区间(Gi_ConfInvl),详细介绍请参阅
hotSpotAnalyst方法结果。2. z得分和P值都是统计显著性的度量,用于逐要素的判断是否拒绝"零假设"。置信区间字段会识别具有统计显著性的热点和冷点。置信区间为+3和-3的要素反映置信度为99%的统计显著性,置信区间为+2和-2的要素反映置信度为95%的统计显著性,置信区间为+1和-1的要素反映置信度为90%的统计显著性,而置信区间为0的要素的聚类则没有统计意义。
3. 如果提供分析字段,则会直接执行热点分析; 如果未提供分析字段,则会利用提供的聚合方法(参阅
AggregationMethod)聚合所有输入事件点以获得计数,从而作为分析字段执行热点分析。4. 执行热点分析时,默认概念化模型为
ConceptualizationModel.FIXEDDISTANCEBAND、错误发现率(FDR)为 true ,统计显著性将使用错误发现率(FDR)校正法自动兼顾多重测试和空间依赖性。5. 调用该方法时,需要通过 optimizedParameter 参数指定一个分析模式参数(
OptimizedParameter)对象,该对象用于热点分析所需的参数,如评估字段、聚合方法等。- 参数:
sourceDatasetVector- 指定的待计算的数据集。可以为点、线、面数据集。targetDatasource- 指定的用于存储结果数据集的数据源。targetDatasetName- 指定的结果数据集名称。optimizedParameter- 指定的优化的热点分析参数设置。listeners- 用于接收进度条事件的监听器。
-
densityBasedClustering
@Deprecated public static DatasetVector densityBasedClustering(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, int minPilePointCount, double searchDistance, Unit unit)
已过时。 此方法已废弃,请使用支持进度监听的新方法ClusteringDistributions.densityBasedClustering(DatasetVector, Datasource, String, int, double, Unit, SteppedListener...)替换。密度聚类分析- 参数:
sourceDatasetVector- 指定的待计算的数据集。可以为点数据集。targetDatasource- 指定的存储结果的数据集所在的数据源targetDatasetName- 指定的结果数据集名称minPilePointCount- 点数目阈值searchDistance- 聚类半径unit- 单位- 返回:
- 结果数据集中包含了 源数据ID(Source_ID)、聚类类别(Cluster_ID)、点顺序(ReachOrder)、可达距离(ReachDist)。Source_ID 为源数据的ID;Cluster_ID 为聚类的结果聚类类别, -1 为噪声点; ReachOrder 为点数据的处理顺序; ReachDist 为可达距离,点到最近聚类类别的最短路径.
-
hierarchicalDensityBasedClustering
@Deprecated public static DatasetVector hierarchicalDensityBasedClustering(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, int minPilePointCount)
已过时。 此方法已废弃,请使用支持进度监听的新方法ClusteringDistributions.hierarchicalDensityBasedClustering(DatasetVector, Datasource, String, int, SteppedListener...)替换。层次密度聚类分析- 参数:
sourceDatasetVector- 指定的待计算的数据集。可以为点数据集。targetDatasource- 指定的存储结果的数据集所在的数据源targetDatasetName- 指定的结果数据集名称minPilePointCount- 点数目阈值- 返回:
- 结果数据集中包含了 源数据ID(Source_ID)、聚类类别(Cluster_ID)、点顺序(ReachOrder)、可达距离(ReachDist)。Source_ID 为源数据的ID;Cluster_ID 为聚类的结果聚类类别, -1 为噪声点; ReachOrder 为点数据的处理顺序; ReachDist 为可达距离,点到最近聚类类别的最短路径.
-
orderingDensityBasedClustering
@Deprecated public static DatasetVector orderingDensityBasedClustering(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, int minPilePointCount, double searchDistance, Unit unit, int clusterSensitivity)
已过时。 此方法已废弃,请使用支持进度监听的新方法ClusteringDistributions.orderingDensityBasedClustering(DatasetVector, Datasource, String, int, double, Unit, int, SteppedListener...)替换。顺序密度聚类分析- 参数:
sourceDatasetVector- 指定的待计算的数据集。可以为点数据集。targetDatasource- 指定的存储结果的数据集所在的数据源targetDatasetName- 指定的结果数据集名称minPilePointCount- 点数目阈值searchDistance- 聚类半径unit- 单位clusterSensitivity- 聚类的紧密度,0到100之间。值越大,产生的聚类簇内的点越密集;值越小,产生的聚类簇内的点越稀疏- 返回:
- 结果数据集中包含了 源数据ID(Source_ID)、聚类类别(Cluster_ID)、点顺序(ReachOrder)、可达距离(ReachDist)。Source_ID 为源数据的ID;Cluster_ID 为聚类的结果聚类类别, -1 为噪声点; ReachOrder 为点数据的处理顺序; ReachDist 为可达距离,点到最近聚类类别的最短路径
-
densityBasedClustering
public static DatasetVector densityBasedClustering(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, int minPilePointCount, double searchDistance, Unit unit, SteppedListener... listeners)
密度聚类分析- 参数:
sourceDatasetVector- 指定的待计算的数据集。可以为点数据集。targetDatasource- 指定的存储结果的数据集所在的数据源targetDatasetName- 指定的结果数据集名称minPilePointCount- 点数目阈值searchDistance- 聚类半径unit- 单位listeners- 用于接收进度条事件的监听器。- 返回:
- 结果数据集中包含了 源数据ID(Source_ID)、聚类类别(Cluster_ID)、点顺序(ReachOrder)、可达距离(ReachDist)。Source_ID 为源数据的ID;Cluster_ID 为聚类的结果聚类类别, -1 为噪声点; ReachOrder 为点数据的处理顺序; ReachDist 为可达距离,点到最近聚类类别的最短路径
-
hierarchicalDensityBasedClustering
public static DatasetVector hierarchicalDensityBasedClustering(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, int minPilePointCount, SteppedListener... listeners)
层次密度聚类分析- 参数:
sourceDatasetVector- 指定的待计算的数据集。可以为点数据集。targetDatasource- 指定的存储结果的数据集所在的数据源targetDatasetName- 指定的结果数据集名称minPilePointCount- 点数目阈值listeners- 用于接收进度条事件的监听器。- 返回:
- 结果数据集中包含了 源数据ID(Source_ID)、聚类类别(Cluster_ID)、点顺序(ReachOrder)、可达距离(ReachDist)。Source_ID 为源数据的ID;Cluster_ID 为聚类的结果聚类类别, -1 为噪声点; ReachOrder 为点数据的处理顺序; ReachDist 为可达距离,点到最近聚类类别的最短路径
-
orderingDensityBasedClustering
public static DatasetVector orderingDensityBasedClustering(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, int minPilePointCount, double searchDistance, Unit unit, int clusterSensitivity, SteppedListener... listeners)
顺序密度聚类分析- 参数:
sourceDatasetVector- 指定的待计算的数据集。可以为点数据集。targetDatasource- 指定的存储结果的数据集所在的数据源targetDatasetName- 指定的结果数据集名称minPilePointCount- 点数目阈值searchDistance- 聚类半径unit- 单位clusterSensitivity- 聚类的紧密度,0到100之间。值越大,产生的聚类簇内的点越密集;值越小,产生的聚类簇内的点越稀疏listeners- 用于接收进度条事件的监听器。- 返回:
- 结果数据集中包含了 源数据ID(Source_ID)、聚类类别(Cluster_ID)、点顺序(ReachOrder)、可达距离(ReachDist)。Source_ID 为源数据的ID;Cluster_ID 为聚类的结果聚类类别, -1 为噪声点; ReachOrder 为点数据的处理顺序; ReachDist 为可达距离,点到最近聚类类别的最短路径
-
kmeans
public static Point2D[] kmeans(DatasetVector sourceDatasetVector, KMeansParameter parameter, SteppedListener... listeners)
K均值聚类,返回聚类中心二维点数组。- 参数:
sourceDatasetVector- 指定的点数据集。parameter- K均值聚类参数。listeners- 进度条事件的监听器。- 返回:
- 返回聚类中心二维点数组。
-
kmeans
public static DatasetVector kmeans(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, KMeansParameter parameter, SteppedListener... listeners)
K均值聚类,返回聚类中心矢量点结果数据集。k均值聚类(k-means)算法是一种迭代求解的聚类分析算法,其原理为预将数据分为K组,选取K个对象作为初始的聚类中心,然后把每个对象分配给最近的初始聚类中心,聚类中心以及分配给它们的对象代表一个聚类。每分配一次样本,聚类中心会被重新计算。这个过程将不断重复直到达到期望结果。迭代的终止条件可以是没有对象被重新分配给不同的聚类,没有聚类中心再发生变化,或者达到最大迭代次数(默认迭代次数:300)。
k均值方法对异常值敏感,因此可以在分析前将异常/离群值剔除,否则会对聚类结果有影响。
输出结果:1、在源数据集中增加了一个 Cluster_ID 字段表示结果聚类类别;2、结果矢量数据集表示最终聚类的K个聚类中心点。
- 参数:
sourceDatasetVector- 指定的点数据集。targetDatasource- 指定的用于存储结果数据集的数据源。targetDatasetName- 指定的结果数据集名称。parameter- K均值聚类参数。listeners- 进度条事件的监听器。- 返回:
- 返回聚类中心点矢量数据集。
-
meanShift
public static Point2D[] meanShift(DatasetVector sourceDatasetVector, MeanShiftParameter parameter, SteppedListener... listeners)
均值偏移聚类,返回聚类中心二维点数组。- 参数:
sourceDatasetVector- 指定的点数据集。parameter- 均值偏移聚类参数。listeners- 进度条事件的监听器。- 返回:
- 聚类中心二维点数组。
-
meanShift
public static DatasetVector meanShift(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, MeanShiftParameter parameter, SteppedListener... listeners)
均值偏移聚类,返回聚类中心矢量点结果数据集。均值偏移聚类(Means Shift算法)是一种基于聚类中心迭代求解的聚类算法,与K均值聚类不同的是不需要事先确定聚类个数K。均值偏移聚类的原理为:从初始聚类中心点开始,沿着带宽内点群密度上升的方向不断寻找新的聚类中心点,直到满足终止条件。终止条件为迭代过程中前后两次聚类的中心移动距离几乎不变 或者达到最大迭代次数(默认迭代次数:300)。
输出结果:1、在源数据集中增加了一个 Cluster_ID 字段表示结果聚类类别;2、结果矢量数据集表示最终聚类的聚类中心点。
- 参数:
sourceDatasetVector- 指定的点数据集。targetDatasource- 指定的用于存储结果数据集的数据源。targetDatasetName- 指定的结果数据集名称。parameter- 均值偏移聚类参数。listeners- 进度条事件的监听器。- 返回:
- 返回聚类中心点矢量数据集。
-
addSteppedListener
public static void addSteppedListener(SteppedListener l)
添加一个进度条事件(SteppedEvent)的监听器。- 参数:
l- 一个用于接收进度条事件的监听器。
-
removeSteppedListener
public static void removeSteppedListener(SteppedListener l)
移除一个进度条事件(SteppedEvent)的监听器。- 参数:
l- 一个用于接收进度条事件的监听器。
-
-