- java.lang.Object
-
- com.supermap.analyst.spatialanalyst.GeneralizeAnalyst
-
public class GeneralizeAnalyst extends Object
概况操作类。该类用于将分辨率较细的栅格数据处理成分辨率较粗的栅格数据,如栅格聚合、重分级、重分类等。另外在进行完栅格或影像数据分类后,可能会存在小斑块、边界不规整等,这时需要对分类结果做进一步处理,我们将这类处理统称为栅格综合数据处理,提供包括众数滤波、扩展、收缩、区域分组、蚕食、边界清理等。用户可以通过 setAnalystSetting() 方法设置栅格分析环境对象(
GridAnalystSetting),来避免调用栅格概况操作接口时重复设置某些参数,如用于存储结果数据的数据源等。
-
-
方法概要
所有方法 静态方法 具体方法 已过时的方法 限定符和类型 方法和说明 static voidaddSteppedListener(SteppedListener l)添加一个进度条事件(SteppedEvent)的监听器。static DatasetGridaggregate(DatasetGrid sourceDataset, int scale, AggregationType aggregationType, boolean isExpanded, boolean isIgnoreNoValue, Datasource targetDatasource, String targetDatasetName)栅格数据聚合,返回结果栅格数据集。static DatasetGridaggregate(DatasetGrid sourceDataset, int scale, AggregationType aggregationType, boolean isExpanded, boolean isIgnoreNoValue, Datasource targetDatasource, String targetDatasetName, SteppedListener... listeners)栅格聚合static DatasetGridboundaryClean(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, BoundaryCleanSortType sortType, boolean isRunTwoTimes)已过时。static DatasetGridboundaryClean(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, BoundaryCleanSortType sortType, boolean isRunTwoTimes, SteppedListener... listeners)边界清理,返回结果栅格数据集。static double[]ComputeRange(DatasetGrid sourceDataset, int count)已过时。static double[]ComputeRange(DatasetVector sourceDataset, String field, int count)已过时。static DatasetVectordissolve(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, DissolveParameter dissolveParameter)已过时。使用dissolve()替代。 矢量数据融合,返回结果矢量数据集。static booleaneliminate(DatasetVector sourceDatasetVector, double regionTolerance, double vertexTolerance, EliminateMode eliminateMode, boolean isDeleteSingleRegion)已过时。使用eliminate()替代。 碎多边形合并,即将数据集中小于指定面积的多边形合并到相邻的多边形中。static DatasetequantResample(Dataset sourceDataset, int equantNumber, ResampleMode resampleMode, Datasource targetDatasource, String targetDatasetName, SteppedListener... listeners)栅格等分重采样。static DatasetGridexpand(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, NeighborNumber neighborNumber, int cellNumber, int[] zoneValues)已过时。static DatasetGridexpand(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, NeighborNumber neighborNumber, int cellNumber, int[] zoneValues, SteppedListener... listeners)扩展,返回结果栅格数据集。static GridAnalystSettinggetAnalystSetting()返回栅格分析环境设置。static DatasetGridmajorityFilter(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, NeighborNumber neighborNumber, MajorityDefinition majorityDefinition)static DatasetGridmajorityFilter(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, NeighborNumber neighborNumber, MajorityDefinition majorityDefinition, SteppedListener... listeners)众数滤波,返回结果栅格数据集。static DatasetGridnibble(DatasetGrid sourceDataset, DatasetGrid maskDataset, DatasetGrid zoneDataset, Datasource targetDatasource, String targetDatasetName, boolean isMaskNoValue, boolean isNibbleNoValue)static DatasetGridnibble(DatasetGrid sourceDataset, DatasetGrid maskDataset, DatasetGrid zoneDataset, Datasource targetDatasource, String targetDatasetName, boolean isMaskNoValue, boolean isNibbleNoValue, SteppedListener... listeners)蚕食,返回结果栅格数据集。static DatasetGridreclass(DatasetGrid sourceDataset, ReclassMappingTable reclassMappingTable, ReclassPixelFormat reclassPixelFormat, Datasource targetDatasource, String targetDatasetName)栅格数据重分级,返回结果栅格数据集。static DatasetGridreclass(DatasetGrid sourceDataset, ReclassMappingTable reclassMappingTable, ReclassPixelFormat reclassPixelFormat, Datasource targetDatasource, String targetDatasetName, SteppedListener... listeners)栅格重分级static RegionGroupResultregionGroup(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, NeighborNumber neighborNumber, boolean isSaveLinkValue)已过时。static RegionGroupResultregionGroup(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, NeighborNumber neighborNumber, boolean isSaveLinkValue, boolean isLinkByNeighbor, int excludedValue)static RegionGroupResultregionGroup(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, NeighborNumber neighborNumber, boolean isSaveLinkValue, boolean isLinkByNeighbor, int excludedValue, SteppedListener... listeners)区域分组。static RegionGroupResultregionGroup(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, NeighborNumber neighborNumber, boolean isSaveLinkValue, SteppedListener... listeners)区域分组。static voidremoveSteppedListener(SteppedListener l)移除一个进度条事件(SteppedEvent)的监听器。static DatasetGridreplace(DatasetGrid sourceDataset, Map<Double,Double> replaceTable, Datasource targetDatasource, String targetDatasetName)栅格数据查找替换。static DatasetGridreplace(DatasetGrid sourceDataset, Map<Double,Double> replaceTable, Datasource targetDatasource, String targetDatasetName, SteppedListener... listeners)栅格数据查找替换static Datasetresample(Dataset sourceDataset, double newCellSize, ResampleMode resampleMode, Datasource targetDatasource, String targetDatasetName)栅格数据重采样,返回结果数据集。static Datasetresample(Dataset sourceDataset, double newCellSize, ResampleMode resampleMode, Datasource targetDatasource, String targetDatasetName, SteppedListener... listeners)栅格重采样static voidsetAnalystSetting(GridAnalystSetting gridAnalystSetting)设置栅格分析环境设置。static DatasetGridshrink(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, NeighborNumber neighborNumber, int cellNumber, int[] zoneValues)已过时。static DatasetGridshrink(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, NeighborNumber neighborNumber, int cellNumber, int[] zoneValues, SteppedListener... listeners)收缩,返回结果栅格数据集。static DatasetGridslice(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, int numberZones, int baseOutputZones)自然分割重分级,适用于分布不均匀的数据。static DatasetGridslice(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, int numberZones, int baseOutputZones, SteppedListener... listeners)自然分割static DatasetGridthin(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, long backOrNoValue)已过时。此方法已废弃,请使用支持进度监听的新方法GeneralizeAnalyst.thin(DatasetGrid, Datasource, String, long, SteppedListener...)替换。static DatasetGridthin(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, long backOrNoValue, SteppedListener... listeners)细化,返回结果栅格数据集。
-
-
-
方法详细资料
-
getAnalystSetting
public static GridAnalystSetting getAnalystSetting()
返回栅格分析环境设置。- 返回:
- 栅格分析环境设置。
-
setAnalystSetting
public static void setAnalystSetting(GridAnalystSetting gridAnalystSetting)
设置栅格分析环境设置。- 参数:
gridAnalystSetting- 栅格分析环境设置。
-
aggregate
public static DatasetGrid aggregate(DatasetGrid sourceDataset, int scale, AggregationType aggregationType, boolean isExpanded, boolean isIgnoreNoValue, Datasource targetDatasource, String targetDatasetName)
栅格数据聚合,返回结果栅格数据集。栅格聚合操作是以整数倍缩小栅格分辨率,生成一个新的分辨率较粗的栅格的过程。此时,每个像元由原栅格数据的一组像元聚合而成,其值由其包含的原栅格的值共同决定,可以取包含栅格的和、最大值、最小值、平均值、中位数。如缩小n(n为大于1的整数)倍,则聚合后栅格的行、列的数目均为原栅格的1/n,也就是单元格大小是原来的n倍。聚合可以通过对数据进行概化,达到清除不需要的信息或者删除微小错误的目的。
下图为栅格聚合的示意图,展示了将左侧的栅格的分辨率整体缩小2倍,聚合方法使用 Min ,分别在忽略无值和考虑无值时的结果。其中灰色格子代表无值。
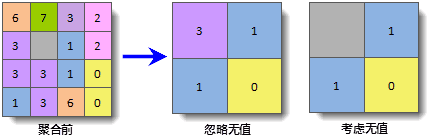
注意:如果原栅格数据的行列数不是 scale 的整数倍,使用 isExpanded 参数来处理零头。
1. isExpanded 为 true,则在零头加上一个数,使之成为一个整数倍,扩大的范围其栅格值均为无值,因此,结果数据集的范围会比原始的大一些。
2. isExpanded 为 false,去掉零头,结果数据集的范围会比原始的小一些。
- 参数:
sourceDataset- 指定的进行聚合操作的栅格数据集。scale- 指定的结果栅格与输入栅格之间栅格大小的比例。取值为大于 1 的整型数值。aggregationType- 指定的聚合操作类型。isExpanded- 指定是否处理零头。当原栅格数据的行列数不是 scale 的整数倍时,栅格边界处则会出现零头。isIgnoreNoValue- 在聚合范围内含有无值数据时聚合操作的计算方式。如果为 true,使用聚合范围内除无值外的其余栅格值来计算;如果为 false,则聚合结果为无值。targetDatasource- 指定的存储结果数据集的数据源。targetDatasetName- 指定的结果数据集的名称。- 返回:
- 结果栅格数据集。
- 示范代码:
- 以下代码示范了如何进行栅格聚合操作,获取结果栅格数据集。示例中使用的聚合类型为取平均值(
AggregationType.AVERRAGE),聚合结果栅格数据分辨率缩小至源数据的四分之一。private DatasetGrid gridAggregate(DatasetGrid sourceDatasetGrid, Datasource targetDatasource) { //设置结果栅格数据集的名称,并检查数据源中是否已存在该数据集,如存在则删除 String targetDatasetName = "resultAggregate"; if (targetDatasource.getDatasets().contains(targetDatasetName)) { targetDatasource.getDatasets().delete(targetDatasetName); } //调用栅格聚合方法,并获取结果数据集 DatasetGrid resultDatasetGrid = GeneralizeAnalyst.aggregate( sourceDatasetGrid, 4, AggregationType.AVERRAGE, false, true, targetDatasource, targetDatasetName); return resultDatasetGrid; }
-
aggregate
public static DatasetGrid aggregate(DatasetGrid sourceDataset, int scale, AggregationType aggregationType, boolean isExpanded, boolean isIgnoreNoValue, Datasource targetDatasource, String targetDatasetName, SteppedListener... listeners)
栅格聚合- 参数:
sourceDataset- [in] 待聚合的栅格数据scale- [in] 结果数据集的分辨率相对原数据的倍数aggregationType- [in] 聚合方法isExpanded- [in] 如果原栅格数据的行列数不是nCellFactor的整数倍,使用isExpanded参数来处理零头isIgnoreNoValue- [in] 如果聚合范围内有空值,就要用isIgnoreNoValue来控制处理。 (1) isIgnoreNoValue=true,使用不是空值的那几个格子计算 (2) isIgnoreNoValue=false,聚合结果为空值targetDatasource- [in] 输出数据所在数据源。targetDatasetName- [in] 输出数据集的名称。- 返回:
- 结果栅格
-
resample
public static Dataset resample(Dataset sourceDataset, double newCellSize, ResampleMode resampleMode, Datasource targetDatasource, String targetDatasetName)
栅格数据重采样,返回结果数据集。栅格数据经过了配准或纠正、投影等几何操作后,栅格的像元中心位置通常会发生变化,其在输入栅格中的位置不一定是整数的行列号,因此需要根据输出栅格上每个格子在输入栅格中的位置,对输入栅格按一定规则进行重采样,进行栅格值的插值计算,建立新的栅格矩阵。不同分辨率的栅格数据之间进行代数运算时,需要将栅格大小统一到一个指定的分辨率上,此时也需要对栅格进行重采样。
栅格重采样有三种常用方法:最邻近法、双线性内插法和三次卷积法。有关这三种重采样方法较为详细的介绍,请参见
ResampleMode类。下图为采用最邻近法,将单元格大小调整为500(原像元大小为70)的栅格重采样的实例。
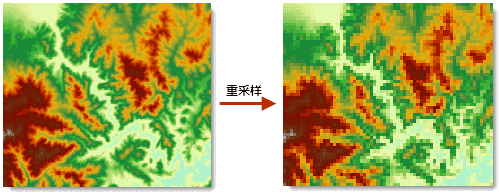
- 参数:
sourceDataset- 指定的用于栅格重采样的数据集。支持影像数据集,包括多波段影像。newCellSize- 指定的结果栅格的单元格大小。resampleMode- 指定的重采样计算方法。targetDatasource- 指定的存储结果数据集的数据源。targetDatasetName- 指定的结果数据集的名称。- 返回:
- 结果数据集。
- 示范代码:
- 以下代码示范了如何进行栅格重采样操作,获取结果数据集。示例将分辨率为 30 的栅格数据重采样为分辨率为 50
的新的栅格数据,使用的重采样方法为最邻近法( @ ResampleMode#NEAREST
ResampleMode.NEAREST} )。
private Dataset rasterResample(Dataset sourceDataset, Datasource targetDatasource) { //设置结果数据集的名称,并检查数据源中是否已存在该数据集,如存在则删除 String targetDatasetName = "resultResample"; if (targetDatasource.getDatasets().contains(targetDatasetName)) { targetDatasource.getDatasets().delete(targetDatasetName); } //调用栅格重采样方法,并获取结果数据集 Dataset resultDataset = GeneralizeAnalyst.resample(sourceDataset, 50, ResampleMode.NEAREST, targetDatasource, targetDatasetName); return resultDataset; }
-
resample
public static Dataset resample(Dataset sourceDataset, double newCellSize, ResampleMode resampleMode, Datasource targetDatasource, String targetDatasetName, SteppedListener... listeners)
栅格重采样- 参数:
sourceDataset- [in] 待重采样的栅格数据(支持影像)newCellSize- [in] 结果栅格的大小resampleMode- [in] 重采样方式targetDatasource- [in] 输出数据所在数据源。targetDatasetName- [in] 输出数据集的名称。- 返回:
- 重采样结果栅格
-
equantResample
public static Dataset equantResample(Dataset sourceDataset, int equantNumber, ResampleMode resampleMode, Datasource targetDatasource, String targetDatasetName, SteppedListener... listeners)
栅格等分重采样。将栅格每个格子等分为[等分数目*等分数目]个小格子。等分指的是格子边长的等分。实际内部创建栅格其实不需要边长,只需要bounds和行列数.所以对原数据的行数和列数分别乘以等分数,便得到新栅格的行列数。
- 参数:
sourceDataset- 待重采样的栅格数据(支持影像)equantNumber- 对原始栅格边长的等分数目,必须大于1resampleMode- 重采样方式targetDatasource- 输出数据所在数据源targetDatasetName- 输出数据集的名称- 返回:
- 重采样结果栅格
-
reclass
public static DatasetGrid reclass(DatasetGrid sourceDataset, ReclassMappingTable reclassMappingTable, ReclassPixelFormat reclassPixelFormat, Datasource targetDatasource, String targetDatasetName)
栅格数据重分级,返回结果栅格数据集。栅格重分级就是对源栅格数据的栅格值进行重新分类和按照新的分类标准赋值,其结果是用新的值取代了栅格数据的原栅格值。对于已知的栅格数据,有时为了便于看清趋势,找出栅格值的规律,或者为了方便进一步的分析,重分级是很必要的:
- 通过重分级,可以使用新值来替代单元格的旧值,以达到更新数据的目的。例如,在处理土地类型变更时,将已经开垦为耕地的荒地赋予新的栅格值;
- 通过重分级,可以对大量的栅格值进行分组归类,同组的单元格赋予相同的值来简化数据。例如,将旱地、水浇地、水田等都归为农业用地;
- 通过重分级,可以对多种栅格数据按照统一的标准进行分类。例如,某个建筑物的选址的影响因素包括土壤和坡度,则对输入的土壤类型和坡度的栅格数据,可以按照 1-10 的等级标准来进行重分级,便于进一步的选址分析;
- 通过重分级,可以将某些不希望参与分析的单元格设为无值,也可以为原先为无值的单元格补充新测定的值,便于进一步的分析处理。
例如,常常需要对栅格表面进行坡度分析得到坡度数据,来辅助与地形有关的分析。但我们可能需要知道坡度属于哪个等级而不是具体的坡度数值,来帮助我们了解地形的陡峭程度,从而辅助进一步的分析,如选址、分析道路铺设线路等。此时可以使用重分级,将不同的坡度划分到对应的等级中。如下图所示,得到坡度图之后,通过重分级将坡度划分为了 8 个等级。
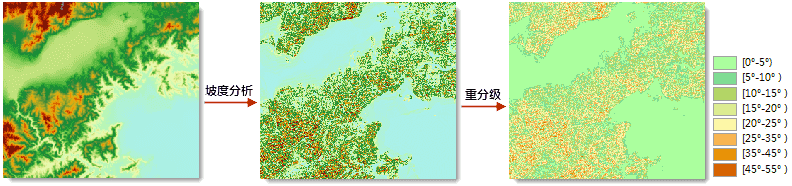
- 参数:
sourceDataset- 指定的进行重分级操作的栅格数据集。reclassMappingTable- 指定的栅格重分级映射表。reclassPixelFormat- 指定的结果数据集的栅格值的存储类型。targetDatasource- 指定的存储结果数据集的数据源。targetDatasetName- 指定的结果数据集的名称。- 返回:
- 结果栅格数据集。
- 示范代码:
- 以下代码示范了如何对栅格数据集进行重分级,获取分级后栅格数据集。除示例中使用的重分级映射表设置方式外,还可以通过导入已有的重分级映射表文件
,请参考
ReclassMappingTable类的介绍。// private DatasetGrid gridReclass(DatasetGrid sourceDatasetGrid, Datasource targetDatasource) { //设置结果栅格数据集的名称,并检查数据源中是否已存在该数据集,如存在则删除 String targetDatasetName = "resultReclass"; if (targetDatasource.getDatasets().contains(targetDatasetName)) { targetDatasource.getDatasets().delete(targetDatasetName); } //设置分级级数为8。将待分级栅格数据的最小值到最大值均分为8份,作为重分级区间集合 int count = 8; ReclassSegment[] arraySegment = new ReclassSegment[count]; double min = sourceDatasetGrid.getMinValue(); double max = sourceDatasetGrid.getMaxValue(); double interval = (max - min) / (double) count; for (int i = 0; i < count; i++) { arraySegment[i] = new ReclassSegment(); arraySegment[i].setStartValue(min + i * interval); arraySegment[i].setEndValue(min + (i + 1) * interval); arraySegment[i].setNewValue(i + 10); arraySegment[i].setSegmentType(ReclassSegmentType.CLOSEOPEN); } //设置栅格重分级映射表 ReclassMappingTable reclassTable = new ReclassMappingTable(); reclassTable.setReclassType(ReclassType.RANGE); reclassTable.setSegments(arraySegment); reclassTable.setRetainMissingValue(false); reclassTable.setChangeMissingValueTo(max); reclassTable.setRetainNoValue(true); //调用栅格重分级方法,并获取结果栅格数据集 DatasetGrid resultDatasetGrid = GeneralizeAnalyst.reclass( sourceDatasetGrid, reclassTable, ReclassPixelFormat.SINGLE, targetDatasource, targetDatasetName); return resultDatasetGrid; }
-
reclass
public static DatasetGrid reclass(DatasetGrid sourceDataset, ReclassMappingTable reclassMappingTable, ReclassPixelFormat reclassPixelFormat, Datasource targetDatasource, String targetDatasetName, SteppedListener... listeners)
栅格重分级- 参数:
sourceDataset- [in] 待重分级的栅格数据reclassMappingTable- [in] 重分级映射表reclassPixelFormat- [in] 结果栅格像素格式targetDatasource- [in] 输出数据所在数据源。targetDatasetName- [in] 输出数据集的名称。- 返回:
- 重分级结果栅格
-
replace
public static DatasetGrid replace(DatasetGrid sourceDataset, Map<Double,Double> replaceTable, Datasource targetDatasource, String targetDatasetName)
栅格数据查找替换。该功能根据查找表,将待操作栅格的某些值替换为新的值,结果为一个新的栅格数据集,源栅格不会被修改。查找表用于记录待操作栅格的值和替换值的对应关系。该方法要求传入一个映射(Map)类型的查找表,映射的键为原值,即源栅格数据集的栅格值,映射的值为对应的替换值,即期望得到的结果栅格数据集的栅格值。
下图为栅格查找替换的示意图,假设源栅格的无值的值为 -9999。注意,无值的值不一定都是 -9999,可以通过 DatasetGrid 的
getNoValue、setNoValue方法返回或设置。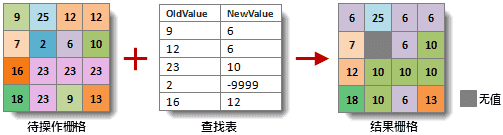
注意:
- 当源栅格的像素类型(
PixelFormat)为整型时,替换值为包含小数位的数值时,最终替换结果将是替换值的整数部分; - 当替换值超出源栅格像素类型的值域时,替换结果将不正确。
- 参数:
sourceDataset- 指定的待操作的栅格数据集。replaceTable- 指定的查找表,用于确定查找替换对应关系,是一个映射(Map)对象,其键代表源栅格值,值代表结果栅格值。targetDatasource- 指定的用于存储结果数据集的数据源。targetDatasetName- 指定的结果栅格数据集的名称。- 返回:
- 进行查找替换操作后的结果栅格数据集。
- 示范代码:
- 以下代码示范了如何进行栅格查找替换。假设在给定的数据源中存在一个名为“Grid”的栅格数据集。
private void replaceExample(Datasource datasource) { //获取待进行查找替换的栅格数据集 DatasetGrid sourceGrid = (DatasetGrid)datasource.getDatasets().get("Grid"); //制作查找表 Map
- 当源栅格的像素类型(
-
replace
public static DatasetGrid replace(DatasetGrid sourceDataset, Map<Double,Double> replaceTable, Datasource targetDatasource, String targetDatasetName, SteppedListener... listeners)
栅格数据查找替换- 参数:
sourceDataset- [in] 待查找替换的栅格数据集replaceTable- [in] 确定查找替换对应关系的字典targetDatasource- [in] 输出数据所在数据源。targetDatasetName- [in] 输出数据集的名称。- 返回:
- 替换后的结果栅格
-
slice
public static DatasetGrid slice(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, int numberZones, int baseOutputZones)
自然分割重分级,适用于分布不均匀的数据。Jenks自然间断法
该重分级方法利用的是Jenks自然间断法。Jenks自然间断法基于数据中固有的自然分组,这是方差最小化分级的形式,间断通常不均匀,且间断 选择在值出现剧烈变动的地方,所以该方法能对相似值进行恰当分组并可使各分级间差异最大化。Jenks间断点分级法会将相似值(聚类值)放置在同一类中,所以该方法适用于分布不均匀的数据值。
如下图所示,图一以重分级区域为9,最低区域值为1自然分割重分级后得到图二的结果:
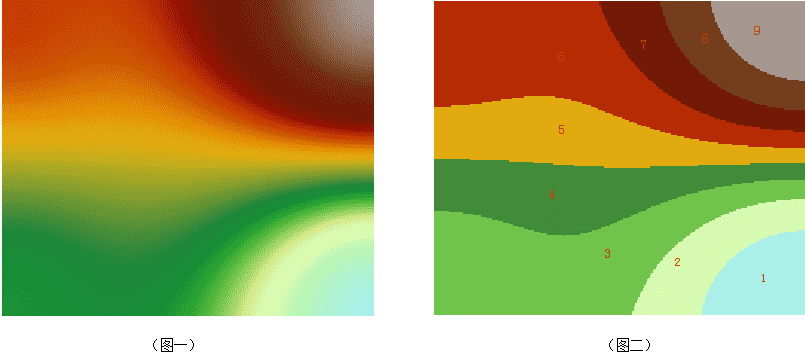
- 参数:
sourceDataset- 指定的进行重分级操作的栅格数据集。targetDatasource- 指定的用于存储结果数据集的数据源。targetDatasetName- 指定的结果数据集名称。numberZones- 将栅格数据集重分级的区域数量。baseOutputZones- 结果栅格数据集中最低区域的值。- 返回:
- 结果栅格数据集。
- 示范代码:
- 以下代码示范了如何对栅格数据集进行自然分割重分级,获取分级后栅格数据集。
// private DatasetGrid gridSlice(DatasetGrid sourceDatasetGrid, Datasource targetDatasource) { //设置结果栅格数据集的名称,并检查数据源中是否已存在该数据集,如存在则删除。 String targetDatasetName = "resultSlice"; if (targetDatasource.getDatasets().contains(targetDatasetName)) { targetDatasource.getDatasets().delete(targetDatasetName); } //设置分级区域数为9,将待分级栅格数据的最小值到最大值自然分割为9份。最低区域值设为1,重分级后的值以1为起始值每级递增。 DatasetGrid resultDatasetGrid = GeneralizeAnalyst.slice(sourceDatasetGrid, targetDatasource,targetDatasetName,9,1); return resultDatasetGrid; }
-
slice
public static DatasetGrid slice(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, int numberZones, int baseOutputZones, SteppedListener... listeners)
自然分割
-
ComputeRange
@Deprecated public static double[] ComputeRange(DatasetGrid sourceDataset, int count)
已过时。获取栅格分割间断值
-
ComputeRange
@Deprecated public static double[] ComputeRange(DatasetVector sourceDataset, String field, int count)
已过时。获取矢量分割间断值
-
addSteppedListener
public static void addSteppedListener(SteppedListener l)
添加一个进度条事件(SteppedEvent)的监听器。- 参数:
l- 一个用于接收进度条事件的监听器。
-
removeSteppedListener
public static void removeSteppedListener(SteppedListener l)
移除一个进度条事件(SteppedEvent)的监听器。- 参数:
l- 一个用于接收进度条事件的监听器。
-
dissolve
@Deprecated public static DatasetVector dissolve(DatasetVector sourceDatasetVector, Datasource targetDatasource, String targetDatasetName, DissolveParameter dissolveParameter)
已过时。 使用dissolve()替代。 矢量数据融合,返回结果矢量数据集。融合是指将融合字段值相同的对象合并为一个简单对象或复杂对象。适用于线对象和面对象。子对象是构成简单对象和复杂对象的基本对象。简单对象由一个子对象组成,即简单对象本身;复杂对象由两个或两个以上相同类型的子对象组成。
调用该方法时,需要通过 dissolveParameter 参数指定一个融合参数(
DissolveParameter)对象,该对象用于指定融合所需的参数,如融合类型、融合字段、融合容限、统计字段及统计类型、过滤表达式,以及是否进行拓扑预处理、是否处理融合字段为空的对象等。矢量数据的融合有三种方式:ONLYMULTIPART(组合)、SINGLE(融合)和 MULTIPART(融合后组合),详细介绍请参见
DissolveType类。- 参数:
sourceDatasetVector- 指定的待融合的矢量数据集。必须为线数据集或面数据集。targetDatasource- 指定的用于存储结构数据集的数据源。targetDatasetName- 指定的结果数据集的名称。dissolveParameter- 指定的融合参数。- 返回:
- 融合结果数据集。
- 抛出:
IllegalArgumentException- 如果 sourceDataset 参数指定的数据集类型不为线或面
-
eliminate
@Deprecated public static boolean eliminate(DatasetVector sourceDatasetVector, double regionTolerance, double vertexTolerance, EliminateMode eliminateMode, boolean isDeleteSingleRegion)
已过时。 使用eliminate()替代。 碎多边形合并,即将数据集中小于指定面积的多边形合并到相邻的多边形中。在数据制作和处理过程中,或对不精确的数据进行叠加后,都可能产生一些细碎而无用的多边形,称为碎多边形。可以通过“碎多边形合并”功能将这些细碎多边形合并到相邻的多边形中,或删除孤立的碎多边形(没有与其他多边形相交或者相切的多边形),以达到简化数据的目的。
一般面积远远小于数据集中其他对象的多边形才被认为是“碎多边形”,通常是同一数据集中最大面积的百万分之一到万分之一间,但可以依据实际研究的需求来设置最小多边形容限。如下图所示的数据中,在较大的多边形的边界上,有很多无用的碎多边形。
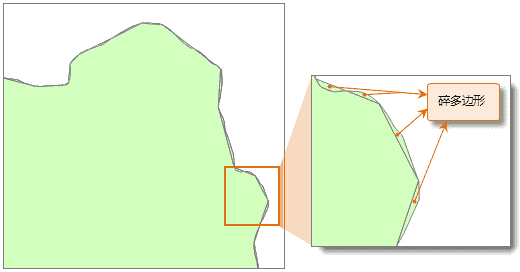
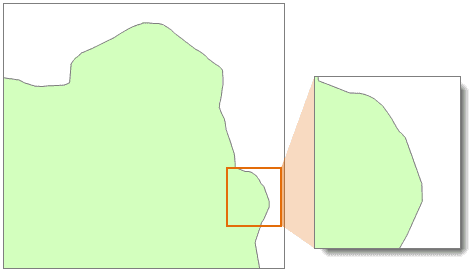
下图是对该数据进行“碎多边形合并”处理后的结果,与上图对比可以看出,碎多边形都被合并到了相邻的较大的多边形中。
注意:
- 该方法适用于两个面具有公共边界的情况,处理后会把公共边界去除。
- 进行碎多边形合并处理后,数据集内的对象数量可能减少。
- 参数:
sourceDatasetVector- 指定的待进行碎多边形合并的数据集。只支持矢量二维面数据集,指定其他类型的数据集会抛出异常。regionTolerance- 指定的最小多边形容限。与系统计算的面积(SmArea 字段的值)对比,小于该值的多边形将被消除。取值范围为大于等于0,指定为小于0的值会抛出异常。vertexTolerance- 指定的节点容限。若两个节点之间的距离小于此容限值,则合并过程中会自动将这两个节点合并为一个节点。取值范围大于等于0,指定为小于0的值会抛出异常。eliminateMode- 指定的碎多边形合并方式。目前仅支持“按面积合并”(EliminateMode.ELIMINATE_BY_AREA)方式,即将碎多边形合并到与其相邻的具有最大面积的多边形中。isDeleteSingleRegion- 指定是否删除孤立的小多边形。如果为 true 会删除孤立的小多边形,否则不删除。- 返回:
- 一个布尔值,如果合并成功返回 true,否则返回 false。
-
majorityFilter
@Deprecated public static DatasetGrid majorityFilter(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, NeighborNumber neighborNumber, MajorityDefinition majorityDefinition)
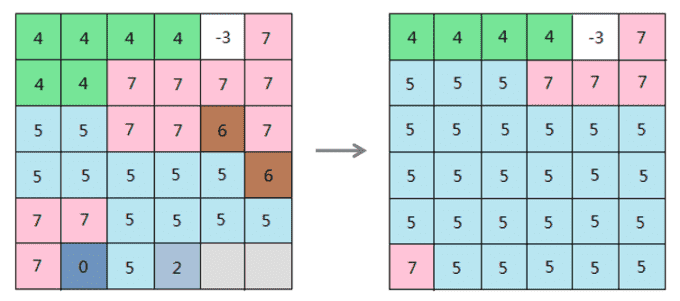
已过时。 此方法已废弃,请使用支持进度监听的新方法GeneralizeAnalyst.majorityFilter(DatasetGrid, Datasource, String, NeighborNumber, MajorityDefinition, SteppedListener...)替换。众数滤波,返回结果栅格数据集。根据相邻像元值的众数替换栅格像元值。众数滤波工具必须满足两个条件才能执行替换。具有相同值的相邻像元数必须足够多(达到所有像元的半数及以上),并且这些像元在滤波器内核周围必须是连续的。第二个条件与像元的空间连通性有关,目的是将像元的空间模式的破坏程度降到最低。
特殊情况:
- 角像元:4邻域情况下相邻像元2个,8邻域情况下相邻像元3个,此时必须连续两个及以上相同值才能发生替换;
- 边像元:4邻域情况下相邻像元3个,此时必须连续2个及以上相同值才能替换;8邻域情况下相邻像元5个,此时必须3个及以上并且至少一个像元在边上才能发生替换。
- 半数相等:有两种值都为半数时其中一种和该像元相同时不替换,不同时随意替换。
下图为众数滤波的示意图。

- 参数:
sourceDataset- 指定的待处理的数据集。输入栅格必须为整型。targetDatasource- 指定的存储结果数据集的数据源。targetDatasetName- 指定的结果数据集的名称。neighborNumber- 邻域像元数。有上下左右4个像元作为邻近像元(FOUR),和相邻8个像元作为邻近像元(EIGHT)两种选择方法。majorityDefinition- 众数定义,即在进行替换之前指定必须具有相同值的相邻(空间连接)像元数。- 返回:
- 结果数据集。
-
majorityFilter
public static DatasetGrid majorityFilter(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, NeighborNumber neighborNumber, MajorityDefinition majorityDefinition, SteppedListener... listeners)
众数滤波,返回结果栅格数据集。根据相邻像元值的众数替换栅格像元值。众数滤波工具必须满足两个条件才能执行替换。具有相同值的相邻像元数必须足够多(达到所有像元的半数及以上),并且这些像元在滤波器内核周围必须是连续的。第二个条件与像元的空间连通性有关,目的是将像元的空间模式的破坏程度降到最低。
特殊情况:
- 角像元:4邻域情况下相邻像元2个,8邻域情况下相邻像元3个,此时必须连续两个及以上相同值才能发生替换;
- 边像元:4邻域情况下相邻像元3个,此时必须连续2个及以上相同值才能替换;8邻域情况下相邻像元5个,此时必须3个及以上并且至少一个像元在边上才能发生替换。
- 半数相等:有两种值都为半数时其中一种和该像元相同时不替换,不同时随意替换。
下图为众数滤波的示意图。
- 参数:
sourceDataset- 指定的待处理的数据集。输入栅格必须为整型。targetDatasource- 指定的存储结果数据集的数据源。targetDatasetName- 指定的结果数据集的名称。neighborNumber- 邻域像元数。有上下左右4个像元作为邻近像元(FOUR),和相邻8个像元作为邻近像元(EIGHT)两种选择方法。majorityDefinition- 众数定义,即在进行替换之前指定必须具有相同值的相邻(空间连接)像元数。listeners- 用于接收进度条事件的监听器。- 返回:
- 结果数据集。
-
expand
@Deprecated public static DatasetGrid expand(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, NeighborNumber neighborNumber, int cellNumber, int[] zoneValues)
已过时。 此方法已废弃,请使用支持进度监听的新方法GeneralizeAnalyst.expand(DatasetGrid, Datasource, String, NeighborNumber, int, int[], SteppedListener...)替换。扩展,返回结果栅格数据集。按指定的像元数目展开指定的栅格区域。将指定的区域值视为前景区域,其余的区域值视为背景区域。通过此方法可使前景区域扩展到背景区域。无值像元将始终被视为背景像元,因此任何值的相邻像元都可以扩展到无值像元,无值像元不会扩展到相邻像元。
注意:
- 只有一种类型区域值时,则扩展该值;
- 多种类型区域值时,首先扩展距离最近的;
- 距离相等的情况下,计算每个区域值的贡献值,扩展总贡献值最大的值(4邻域法和8邻域法的贡献值计算方式不同);
- 距离和贡献值相等,则扩展像元值最小的。
下图为扩展的示意图。
- 参数:
sourceDataset- 指定的待处理的数据集。输入栅格必须为整型。targetDatasource- 指定的存储结果数据集的数据源。targetDatasetName- 指定的结果数据集的名称。neighborNumber- 邻域像元数,在这里指用于扩展所选区域的方法。有基于距离的方法,即上下左右4个像元作为邻近像元(FOUR),和基于数学形态学的方法,即相邻8个像元作为邻近像元(EIGHT)两种扩展方法。cellNumber- 按照所选邻域扩展方法(4领域/8邻域)进行收缩的次数。其中上一次运行的结果是后续迭代的输入,该值必须为大于0的整数。zoneValues- 要进行扩展的像元区域值。- 返回:
- 结果栅格数据集。
-
expand
public static DatasetGrid expand(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, NeighborNumber neighborNumber, int cellNumber, int[] zoneValues, SteppedListener... listeners)
扩展,返回结果栅格数据集。按指定的像元数目展开指定的栅格区域。将指定的区域值视为前景区域,其余的区域值视为背景区域。通过此方法可使前景区域扩展到背景区域。无值像元将始终被视为背景像元,因此任何值的相邻像元都可以扩展到无值像元,无值像元不会扩展到相邻像元。
注意:
- 只有一种类型区域值时,则扩展该值;
- 多种类型区域值时,首先扩展距离最近的;
- 距离相等的情况下,计算每个区域值的贡献值,扩展总贡献值最大的值(4邻域法和8邻域法的贡献值计算方式不同);
- 距离和贡献值相等,则扩展像元值最小的。
下图为扩展的示意图。
- 参数:
sourceDataset- 指定的待处理的数据集。输入栅格必须为整型。targetDatasource- 指定的存储结果数据集的数据源。targetDatasetName- 指定的结果数据集的名称。neighborNumber- 邻域像元数,在这里指用于扩展所选区域的方法。有基于距离的方法,即上下左右4个像元作为邻近像元(FOUR),和基于数学形态学的方法,即相邻8个像元作为邻近像元(EIGHT)两种扩展方法。cellNumber- 按照所选邻域扩展方法(4领域/8邻域)进行收缩的次数。其中上一次运行的结果是后续迭代的输入,该值必须为大于0的整数。zoneValues- 要进行扩展的像元区域值。listeners- 用于接收进度条事件的监听器。- 返回:
- 结果栅格数据集。
-
shrink
@Deprecated public static DatasetGrid shrink(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, NeighborNumber neighborNumber, int cellNumber, int[] zoneValues)
已过时。 此方法已废弃,请使用支持进度监听的新方法GeneralizeAnalyst.shrink(DatasetGrid, Datasource, String, NeighborNumber, int, int[], SteppedListener...)替换。收缩,返回结果栅格数据集。按指定的像元数目收缩所选区域,方法是用邻域中出现最频繁的像元值替换该区域的值。将指定的区域值视为前景区域,其余的区域值视为背景区域。通过此方法可用背景区域中的像元来替换前景区域中的像元。
注意:
- 收缩有多个值时,取出现最频繁的,如果多个值个数相同则取随机值;
- 两个相邻区域都是要收缩的像元,则在边界上没有任何变化;
- 无值为有效值,即与无值数据相邻的像元有可能被替换为无值。
下图为收缩的示意图。
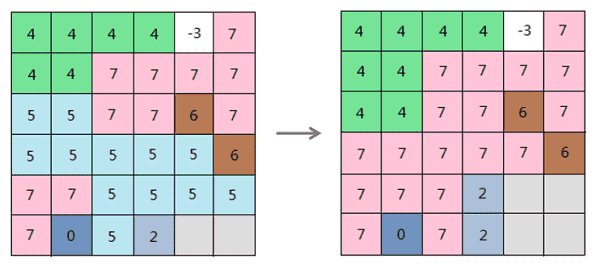
- 参数:
sourceDataset- 指定的待处理的数据集。输入栅格必须为整型。targetDatasource- 指定的存储结果数据集的数据源。targetDatasetName- 指定的结果数据集的名称。neighborNumber- 邻域像元数,在这里指用于收缩所选区域的方法。有基于距离的方法,即上下左右4个像元作为邻近像元(FOUR),和基于数学形态学的方法,即相邻8个像元作为邻近像元(EIGHT)两种收缩方法。cellNumber- 按照所选邻域收缩方法(4领域/8邻域)进行收缩的次数。其中上一次运行的结果是后续迭代的输入,该值必须为大于0的整数。zoneValues- 要进行收缩的像元区域值。- 返回:
- 结果栅格数据集。
-
shrink
public static DatasetGrid shrink(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, NeighborNumber neighborNumber, int cellNumber, int[] zoneValues, SteppedListener... listeners)
收缩,返回结果栅格数据集。按指定的像元数目收缩所选区域,方法是用邻域中出现最频繁的像元值替换该区域的值。将指定的区域值视为前景区域,其余的区域值视为背景区域。通过此方法可用背景区域中的像元来替换前景区域中的像元。
注意:
- 收缩有多个值时,取出现最频繁的,如果多个值个数相同则取随机值;
- 两个相邻区域都是要收缩的像元,则在边界上没有任何变化;
- 无值为有效值,即与无值数据相邻的像元有可能被替换为无值。
下图为收缩的示意图。
- 参数:
sourceDataset- 指定的待处理的数据集。输入栅格必须为整型。targetDatasource- 指定的存储结果数据集的数据源。targetDatasetName- 指定的结果数据集的名称。neighborNumber- 邻域像元数,在这里指用于收缩所选区域的方法。有基于距离的方法,即上下左右4个像元作为邻近像元(FOUR),和基于数学形态学的方法,即相邻8个像元作为邻近像元(EIGHT)两种收缩方法。cellNumber- 按照所选邻域收缩方法(4领域/8邻域)进行收缩的次数。其中上一次运行的结果是后续迭代的输入,该值必须为大于0的整数。zoneValues- 要进行收缩的像元区域值。listeners- 用于接收进度条事件的监听器。- 返回:
- 结果栅格数据集。
-
regionGroup
@Deprecated public static RegionGroupResult regionGroup(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, NeighborNumber neighborNumber, boolean isSaveLinkValue, boolean isLinkByNeighbor, int excludedValue)
已过时。 此方法已废弃,请使用支持进度监听的新方法GeneralizeAnalyst.regionGroup(DatasetGrid, Datasource, String, NeighborNumber, boolean, boolean, int, SteppedListener...)替换。区域分组。记录输出中每个像元所属的连接区域的标识,系统为每个区域分配唯一编号,简单来说就是将连通的具有相同值的像元组成一个区域并编号。扫描的第一个区域赋值为1,第二个区域赋值为2,依此类推,直到所有的区域均已赋值。扫描将按从左至右、从上至下的顺序进行。
下图为区域分组的示意图。
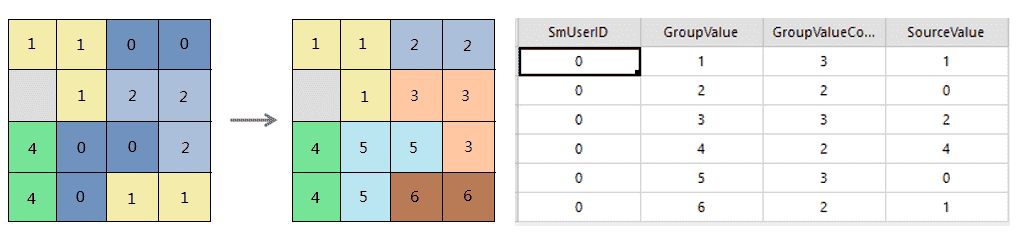
- 参数:
sourceDataset- 指定的待处理的数据集。输入栅格必须为整型。targetDatasource- 指定的存储结果数据集的数据源。targetDatasetName- 指定的结果数据集的名称。neighborNumber- 邻域像元数。有上下左右4个像元作为邻近像元(FOUR),和相邻8个像元作为邻近像元(EIGHT)两种选择方法。isSaveLinkValue- 是否保留对应的栅格原始值。设置为true,属性表增加SourceValue项,连接输入栅格的每个像元的原始值;如果不再需要每个区域的原始值,可以设置为false,会加速处理过程。注意,只有当isLinkByNeighbor 设置为true时,该参数才有效。isLinkByNeighbor- 是否根据邻域连通。设置为true时,根据4邻域或8邻域法连通像元构成区域;设置为false时,必须设置排除值excludedValue,此时除了排除值的连通区域都可以构成一个区域。excludedValue- 排除值。排除的栅格值不参与计数,在输出栅格上,包含排除值的像元位置赋值为0。如果设置了排除值,结果属性表中就没有连接信息。- 返回:
- 结果栅格数据集和属性表。
-
regionGroup
public static RegionGroupResult regionGroup(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, NeighborNumber neighborNumber, boolean isSaveLinkValue, boolean isLinkByNeighbor, int excludedValue, SteppedListener... listeners)
区域分组。记录输出中每个像元所属的连接区域的标识,系统为每个区域分配唯一编号,简单来说就是将连通的具有相同值的像元组成一个区域并编号。扫描的第一个区域赋值为1,第二个区域赋值为2,依此类推,直到所有的区域均已赋值。扫描将按从左至右、从上至下的顺序进行。
下图为区域分组的示意图。
- 参数:
sourceDataset- 指定的待处理的数据集。输入栅格必须为整型。targetDatasource- 指定的存储结果数据集的数据源。targetDatasetName- 指定的结果数据集的名称。neighborNumber- 邻域像元数。有上下左右4个像元作为邻近像元(FOUR),和相邻8个像元作为邻近像元(EIGHT)两种选择方法。isSaveLinkValue- 是否保留对应的栅格原始值。设置为true,属性表增加SourceValue项,连接输入栅格的每个像元的原始值;如果不再需要每个区域的原始值,可以设置为false,会加速处理过程。注意,只有当isLinkByNeighbor 设置为true时,该参数才有效。isLinkByNeighbor- 是否根据邻域连通。设置为true时,根据4邻域或8邻域法连通像元构成区域;设置为false时,必须设置排除值excludedValue,此时除了排除值的连通区域都可以构成一个区域。excludedValue- 排除值。排除的栅格值不参与计数,在输出栅格上,包含排除值的像元位置赋值为0。如果设置了排除值,结果属性表中就没有连接信息。listeners- 用于接收进度条事件的监听器。- 返回:
- 结果栅格数据集和属性表。
-
regionGroup
@Deprecated public static RegionGroupResult regionGroup(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, NeighborNumber neighborNumber, boolean isSaveLinkValue)
已过时。 此方法已废弃,请使用支持进度监听的新方法GeneralizeAnalyst.regionGroup(DatasetGrid, Datasource, String, NeighborNumber, boolean, SteppedListener...)替换。区域分组。记录输出中每个像元所属的连接区域的标识。系统为每个区域分配唯一编号。扫描的第一个区域赋值为1,第二个区域赋值为2,依此类推,直到所有的区域均已赋值。扫描将按从左至右、从上至下的顺序进行。
- 参数:
sourceDataset- 指定的待处理的数据集。输入栅格必须为整型。targetDatasource- 指定的存储结果数据集的数据源。targetDatasetName- 指定的结果数据集的名称。neighborNumber- 邻域像元数。有上下左右4个像元作为邻近像元(FOUR),和相邻8个像元作为邻近像元(EIGHT)两种选择方法。isSaveLinkValue- 是否保留对应的栅格原始值。设置为true,属性表增加SourceValue项,连接输入栅格的每个像元的原始值;如果不再需要每个区域的原始值,可以设置为false,会加速处理过程。- 返回:
- 结果栅格数据集和属性表。
-
regionGroup
public static RegionGroupResult regionGroup(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, NeighborNumber neighborNumber, boolean isSaveLinkValue, SteppedListener... listeners)
区域分组。记录输出中每个像元所属的连接区域的标识。系统为每个区域分配唯一编号。扫描的第一个区域赋值为1,第二个区域赋值为2,依此类推,直到所有的区域均已赋值。扫描将按从左至右、从上至下的顺序进行。
- 参数:
sourceDataset- 指定的待处理的数据集。输入栅格必须为整型。targetDatasource- 指定的存储结果数据集的数据源。targetDatasetName- 指定的结果数据集的名称。neighborNumber- 邻域像元数。有上下左右4个像元作为邻近像元(FOUR),和相邻8个像元作为邻近像元(EIGHT)两种选择方法。isSaveLinkValue- 是否保留对应的栅格原始值。设置为true,属性表增加SourceValue项,连接输入栅格的每个像元的原始值;如果不再需要每个区域的原始值,可以设置为false,会加速处理过程。listeners- 用于接收进度条事件的监听器。- 返回:
- 结果栅格数据集和属性表。
-
nibble
@Deprecated public static DatasetGrid nibble(DatasetGrid sourceDataset, DatasetGrid maskDataset, DatasetGrid zoneDataset, Datasource targetDatasource, String targetDatasetName, boolean isMaskNoValue, boolean isNibbleNoValue)
已过时。 此方法已废弃,请使用支持进度监听的新方法GeneralizeAnalyst.nibble(DatasetGrid, DatasetGrid, DatasetGrid, Datasource, String, boolean, boolean, SteppedListener...)替换。蚕食,返回结果栅格数据集。用最邻近点的值替换掩膜范围内的栅格像元值。蚕食可将最近邻域的值分配给栅格中的所选区域,可用于编辑某栅格中已知数据存在错误的区域。
一般来说掩膜栅格中值为无值的像元定义哪些像元被蚕食。输入栅格中任何不在掩膜范围内的位置均不会被蚕食。
下图为蚕食的示意图。

- 参数:
sourceDataset- 指定的待处理的数据集。输入栅格可以为整型,也可以为浮点型。maskDataset- 指定的作为掩膜的栅格数据集。zoneDataset- 区域栅格。如果有区域栅格,掩膜内的像元只会被区域栅格中同一区域的最近像元(非掩膜的值)替换。区域是指栅格中具有相同值的连通像元。targetDatasource- 指定的存储结果数据集的数据源。targetDatasetName- 指定的结果数据集的名称。isMaskNoValue- 是否选择掩膜中无值像元被蚕食。true表示选择无值像元被蚕食,即把掩膜中为无值的对应原栅格值替换为最邻近区域的值,有值像元在原栅格中保持不变;false表示选择有值像元被蚕食,即把掩膜中为有值的对应原栅格值替换为最邻近区域的值,无值像元在原栅格中保持不变。一般使用第一种情况较多。isNibbleNoValue- 是否修改原栅格中的无值数据。true表示输入栅格中的无值像元在输出中仍为无值;false表示输入栅格中处于掩膜内的无值像元可以被蚕食为有效的输出像元值。- 返回:
- 结果数据集。
-
nibble
public static DatasetGrid nibble(DatasetGrid sourceDataset, DatasetGrid maskDataset, DatasetGrid zoneDataset, Datasource targetDatasource, String targetDatasetName, boolean isMaskNoValue, boolean isNibbleNoValue, SteppedListener... listeners)
蚕食,返回结果栅格数据集。用最邻近点的值替换掩膜范围内的栅格像元值。蚕食可将最近邻域的值分配给栅格中的所选区域,可用于编辑某栅格中已知数据存在错误的区域。
一般来说掩膜栅格中值为无值的像元定义哪些像元被蚕食。输入栅格中任何不在掩膜范围内的位置均不会被蚕食。
下图为蚕食的示意图。
- 参数:
sourceDataset- 指定的待处理的数据集。输入栅格可以为整型,也可以为浮点型。maskDataset- 指定的作为掩膜的栅格数据集。zoneDataset- 区域栅格。如果有区域栅格,掩膜内的像元只会被区域栅格中同一区域的最近像元(非掩膜的值)替换。区域是指栅格中具有相同值targetDatasource- 指定的存储结果数据集的数据源。targetDatasetName- 指定的结果数据集的名称。isMaskNoValue- 是否选择掩膜中无值像元被蚕食。true表示选择无值像元被蚕食,即把掩膜中为无值的对应原栅格值替换为最邻近区域的值,有值像元在原栅格中保持不变;false表示选择有值像元被蚕食,即把掩膜中为有值的对应原栅格值替换为最邻近区域的值,无值像元在原栅格中保持不变。一般使用第一种情况较多。isNibbleNoValue- 是否修改原栅格中的无值数据。true表示输入栅格中的无值像元在输出中仍为无值;false表示输入栅格中处于掩膜内的无值像元可以被蚕食为有效的输出像元值。listeners- 用于接收进度条事件的监听器。- 返回:
- 结果数据集。
-
boundaryClean
@Deprecated public static DatasetGrid boundaryClean(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, BoundaryCleanSortType sortType, boolean isRunTwoTimes)
已过时。 此方法已废弃,请使用支持进度监听的新方法GeneralizeAnalyst.boundaryClean(DatasetGrid, Datasource, String, BoundaryCleanSortType, boolean, SteppedListener...)替换。边界清理,返回结果栅格数据集。通过扩展和收缩来平滑区域间的边界。将更改x和y方向上所有少于三个像元的区域。
下图为边界清理的示意图。
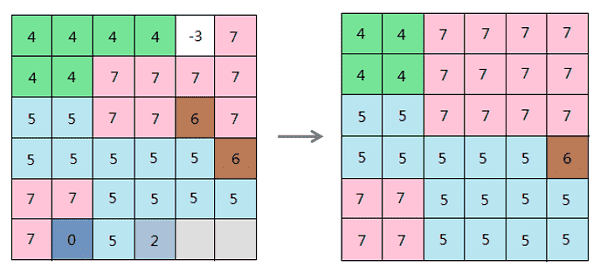
- 参数:
sourceDataset- 指定的待处理的数据集。输入栅格必须为整型。targetDatasource- 指定的存储结果数据集的数据源。targetDatasetName- 指定的结果数据集的名称。sortType- 排序方法。指定要在平滑处理中使用的排序类型。包括NOSORT、DESCEND、ASCEND三种方法。isRunTwoTimes- 发生平滑处理过程的次数是否为两次。true表示执行两次扩展-收缩过程,根据排序类型执行扩展和收缩,然后使用相反的优先级多执行一次收缩和扩展;false表示根据排序类型执行一次扩展和收缩。- 返回:
- 结果栅格数据集。
-
boundaryClean
public static DatasetGrid boundaryClean(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, BoundaryCleanSortType sortType, boolean isRunTwoTimes, SteppedListener... listeners)
边界清理,返回结果栅格数据集。通过扩展和收缩来平滑区域间的边界。将更改x和y方向上所有少于三个像元的区域。
下图为边界清理的示意图。
- 参数:
sourceDataset- 指定的待处理的数据集。输入栅格必须为整型。targetDatasource- 指定的存储结果数据集的数据源。targetDatasetName- 指定的结果数据集的名称。sortType- 排序方法。指定要在平滑处理中使用的排序类型。包括NOSORT、DESCEND、ASCEND三种方法。isRunTwoTimes- 发生平滑处理过程的次数是否为两次。true表示执行两次扩展-收缩过程,根据排序类型执行扩展和收缩,然后使用相反的优先级多执行一次收缩和扩展;false表示根据排序类型执行一次扩展和收缩。listeners- 用于接收进度条事件的监听器。- 返回:
- 结果栅格数据集。
-
thin
@Deprecated public static DatasetGrid thin(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, long backOrNoValue)
已过时。 此方法已废弃,请使用支持进度监听的新方法GeneralizeAnalyst.thin(DatasetGrid, Datasource, String, long, SteppedListener...)替换。细化,返回结果栅格数据集。通过减少表示要素宽度的像元数来对栅格化的线状要素进行细化。典型应用是对扫描的等高线地图进行处理。
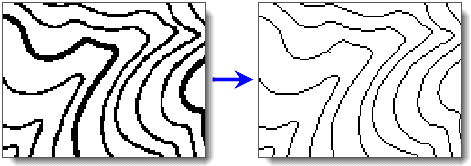
- 参数:
sourceDataset- 指定的待处理的数据集。targetDatasource- 指定的存储结果数据集的数据源。targetDatasetName- 指定的结果数据集的名称。backOrNoValue- 指定的指定栅格的背景色或表示无值的值。- 返回:
- 结果栅格数据集。
-
thin
public static DatasetGrid thin(DatasetGrid sourceDataset, Datasource targetDatasource, String targetDatasetName, long backOrNoValue, SteppedListener... listeners)
细化,返回结果栅格数据集。通过减少表示要素宽度的像元数来对栅格化的线状要素进行细化。典型应用是对扫描的等高线地图进行处理。
- 参数:
sourceDataset- 指定的待处理的数据集。targetDatasource- 指定的存储结果数据集的数据源。targetDatasetName- 指定的结果数据集的名称。backOrNoValue- 指定的指定栅格的背景色或表示无值的值。listeners- 用于接收进度条事件的监听器。- 返回:
- 结果栅格数据集。
-
-