
HBase集群的搭建和使用 |
HBase是一款建立在Hadoop文件系统之上的开源的分布式面向列的数据库,采用横向扩展架构。HBase是一个数据模型,类似于谷歌的大表设计,可以提供快速随机访问海量结构化数据,并利用了Hadoop的文件系统(HDFS)提供的容错能力。HBase作为Hadoop文件系统的一部分,提供了对数据的随机实时读/写访问。人们可以通过HBase对大数据进行随机,实时读/写访问。
本文将带领您搭建一个HBase集群系统。
准备3台ubuntu-15.10操作系统,一台作为集群的主节点(master),其余两台作为工作节点(worker),本例使用的三台设备的IP分别为:
依照上述内容在三台ubuntu上分别配置hosts:
192.168.13.105 master
192.168.13.52 worker1
192.168.13.199 worker2
需在每台设备中安装JDK,下载地址为https://www.oracle.com/technetwork/java/javase/downloads/index.html。本文将带领您安装jdk-8u111-linux-x64.tar.gz,步骤如下:
mkdir /usr/lib/jdk
mv jdk1.8.0_111 /usr/lib/jdk/jdk1.8
方法一:修改全局配置文件,可作用于所有用户,输入如下命令打开全局配置文件:
vi /etc/profile
输入以下内容:
export JAVA_HOME=/usr/lib/jdk/jdk1.8
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=.:${JAVA_HOME}/bin:$PATH
方法二:修改当前用户配置文件,只作用于当前用户,输入如下命令开始编辑:
vi ~/.bashrc
输入的内容同上。
source /etc/profile
或
source ~/.bashrc
java -version
分别在master和worker上执行:
ssh-keygen -t rsa -P
其中,-P表示密码,选填,默认需要三次回车。
执行完命令后,在/home/hdfs/.ssh目录下生成如下两个文件:
分别在master和worker上执行以下命令
ssh-copy-id -i /home/hdfs/.ssh/id_rsa.pub [ip] (自己的ip)
其中,当在master节点上还需执行
ssh-copy-id -i /home/hdfs/.ssh/id_rsa.pub ip(worker的ip)
在master和worker上执行如下命令,验证配置是否成功:
ssh worker/master
先进入配置文件的路径,例如:../etc/hadoop,然后输入ls命令查看该路径下的文件列表。
红框中的文件是需要配置的文件。
首先配置core-site.xml文件。输入如下命令开始编辑:
vi core-site.xml
编辑内容如图:
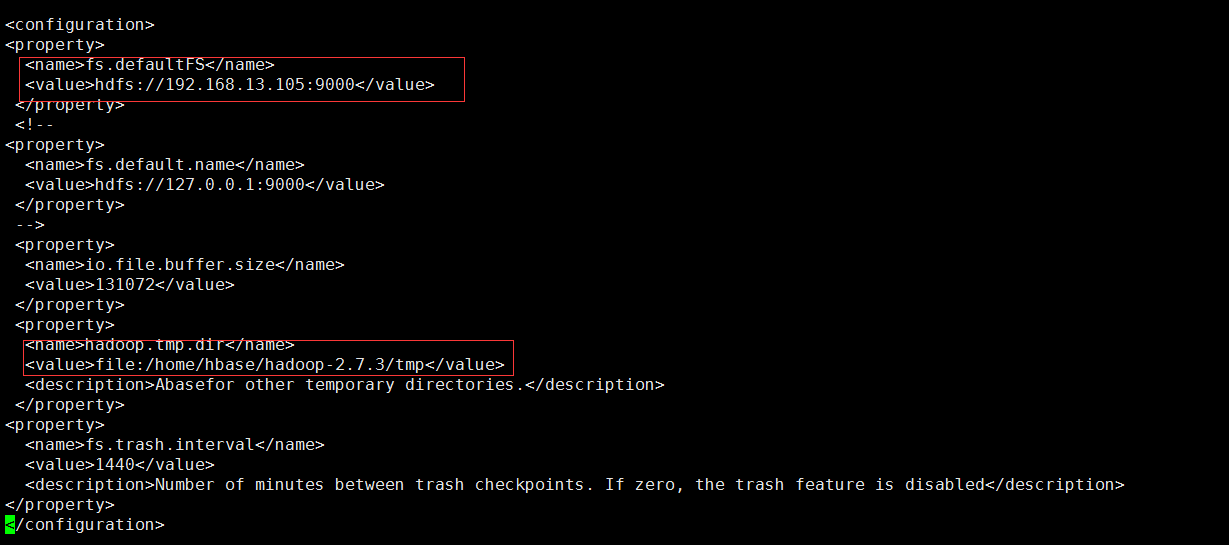
注意:hadoop.tmp.dir属性中的value和步骤1中创建的.. /tmp路径要一致。
配置 hadoop-env.sh文件,输入如下命令开始编辑:
vi hadoop-env.sh

将JAVA_HOME文件配置为本机JAVA_HOME路径
配置 yarn-env.sh。输入如下命令开始编辑:
vi yarn-env.sh
将其中的JAVA_HOME修改为本机JAVA_HOME路径(先把这一行的#去掉)
配置hdfs-site.xml,输入如下命令开始编辑:
vi hdfs-site.xml
在<configuration></configuration>中加入以下代码:
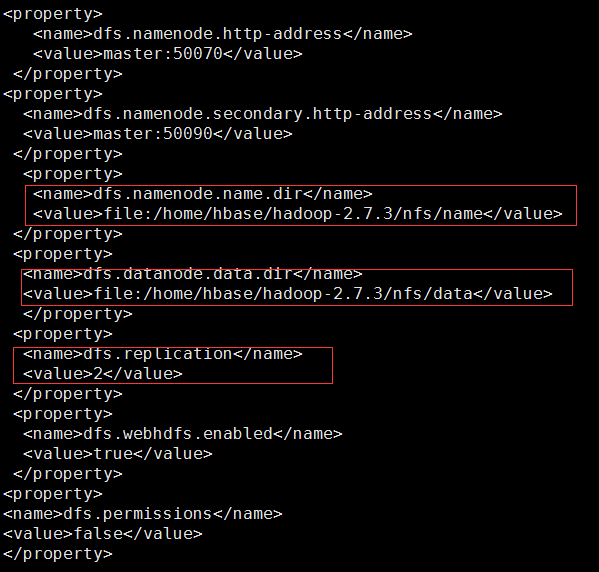
注意:其中dfs.namenode.name.dir和dfs.datanode.data.dir的value和步骤1创建的../nfs/name和..nfs/data需一致;因为这里只有两个子节点,所以dfs.replication设置为2
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
在标签<configuration>中添加以下代码:

vi yarn-site.xml
在<configuration>标签中添加以下代码:
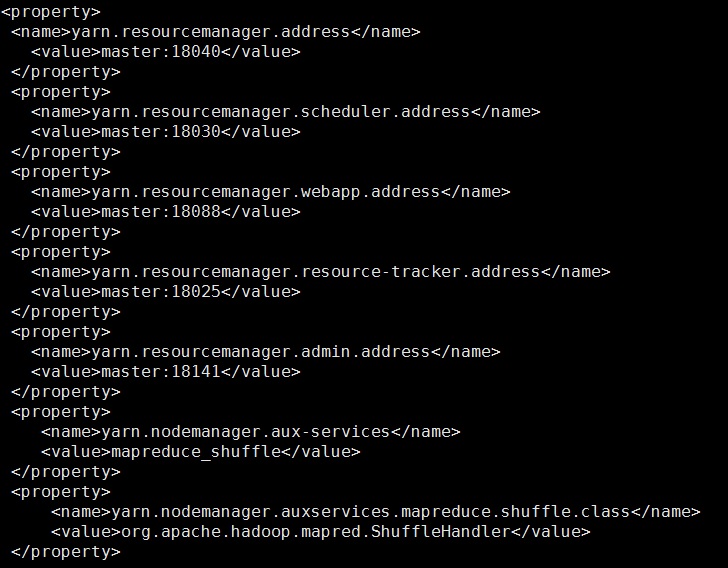
vi slaves
把原本的localhost删掉,改为两个子节点的主机名:

vi masters
改为主节点的主机名:

vi /etc/profile
键入命令 source /etc/profile 使配置立即生效

scp -r hadoop-2.7.3 root@worker1: /home/hbase
scp -r hadoop-2.7.3 root@worker2: /home/hbase
注意:root是ubuntu的用户名,创建worker1和worker2时设定的
传过去后,在worker1和worker2上面同样对Hadoop进行路径配置,和步骤10一样
[root@master bin]$ ./hadoop namenode –format
[root@master sbin]$ ./start-dfs.sh
[root@master sbin]$ ./start-yarn.sh
在mater上面键入jps后,显示如下:

在worker1和worker2节点中键入jps后,显示如下:
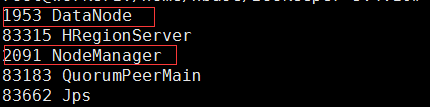
则说明集群搭建成功。
最后,通过访问主节点的IP:http://192.168.13.105:50070,出现以下界面,hadoop集群搭建成功:

在 Hadoop 集群下新建/hbase目录(用于Hbase集群创建)
hadoop fs -mkdir /hbase
通过点击Browse the file system查看
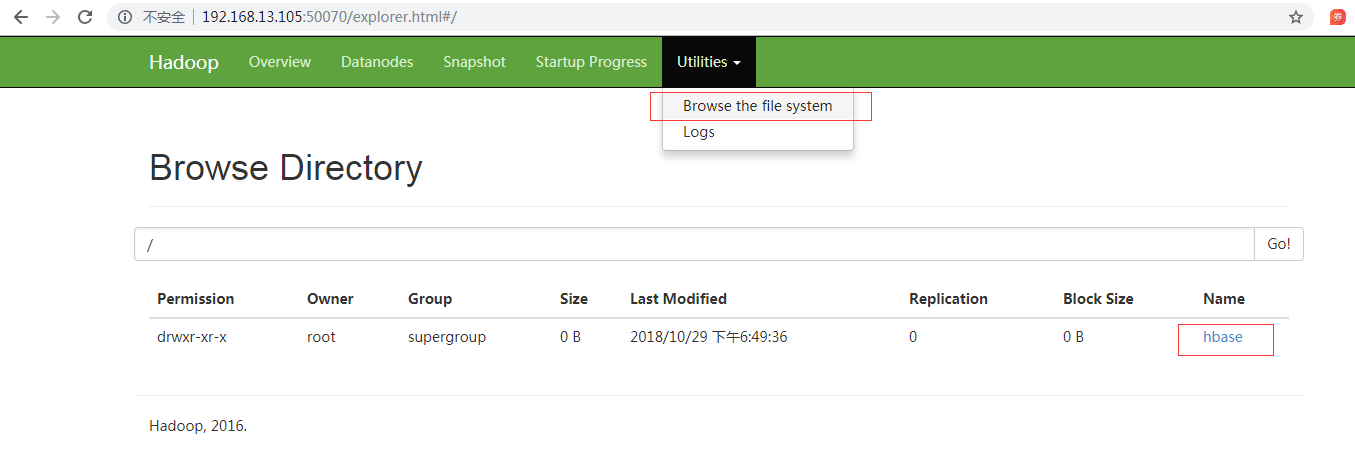
如果不能创建,报连接失败,请仔细检查../conf/hdfs-site.xml和/etc/hosts文件是否有配置多余的连接路径。
ZooKeeper是一个为分布式应用提供一致性服务的软件,是Hadoop和Hbase的重要组件。其架构图如下:
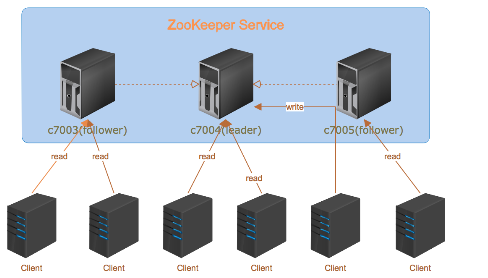
其中,follower负责响应读请求,leader负责提交写请求。
Zookeeper安装步骤如下:
tar -zxvf zookeeper-3.4.10.tar.gz
增加文件权限:
chmod +wxr zookeeper-3.4.10
cd zookeeper-3.4.10
mkdir data
mkdir logs
注意:在../ zookeeper-3.4.10/conf/目录下将zoo_sample.cfg重命名为zoo.cfg(只能存在一个)。
编辑重命名后的zoo.cfg文件
vi conf/zoo.cfg
编辑内容如下:
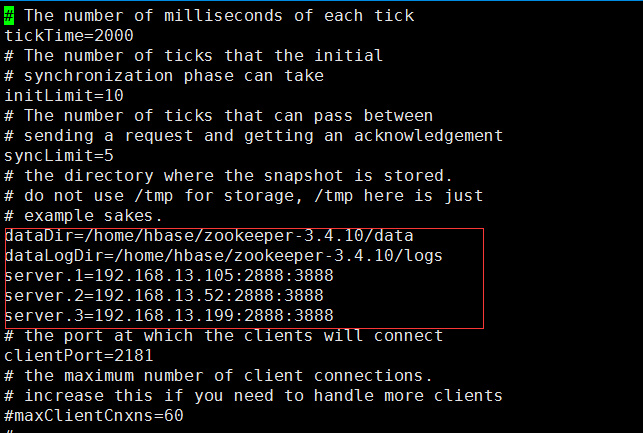
进入data目录,编辑myid
cd data
vi myid

与zoo.cfg文件保持一致(server.1)
scp -r zookeeper-3.4.10 root@worker1:/home/hbase/zookeeper-3.4.10
scp -r zookeeper-3.4.10 root@worker2:/home/hbase/zookeeper-3.4.10
vi myid
[root@master zookeeper-3.4.10]$ bin/zkServer.sh start
[root@worker1 zookeeper-3.4.10]$ bin/zkServer.sh start
[root@worker2 zookeeper-3.4.10]$ bin/zkServer.sh start
[root@master zookeeper-3.4.10]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hbase/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: follower
[root@worker1 zookeeper-3.4.10]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hbase /zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: leader
[root@worker2 zookeeper-3.4.10]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hbase /zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: follower
[root@master zookeeper-3.4.10]$ bin/zkCli.sh -server c7003:2181
当出现Welcome to ZooKeeper! 时,则表示ZooKeeper集群安装完毕!
其他注意事项:
tar -zxvf hbase-1.3.0-bin.tar.gz
vi /etc/profile
输入如下内容:

输入命令source /etc/profile,使之立即生效
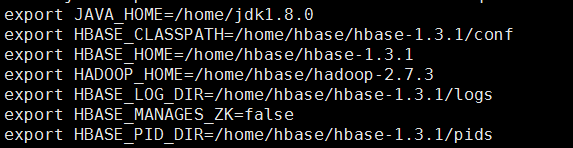
在 ../hbase-1.3.1下新建pids目录
vi hbase-site.xml
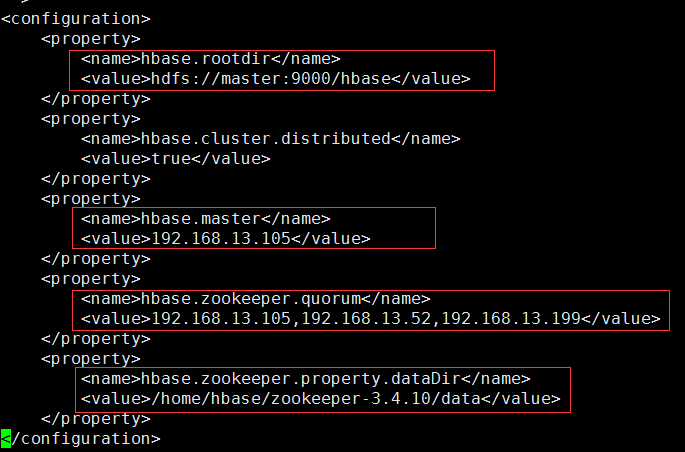
其中:
若 HBase 中数据为矢量数据,除以上配置外还需在该配置文件中增加一个配置:
<property>
<name>hbase.coprocessor.user.region.classes</name>
<value>org.locationtech.geomesa.hbase.coprocessor.GeoMesaCoprocessor</value>
</property>
vi regionservers
删除localhost,加入如下内容:
worker1
worker2
注意:此步骤必须使用【iServer 安装包】/support/GeomesaHBase 目录下的 geomesa-hbase-distributed-runtime.jar,不能从其他途径获取。
scp -r hbase-1.3.1 root@worker1:/home/hbase/ hbase-1.3.1
scp -r hbase-1.3.1 root@worker2:/home/hbase/ hbase-1.3.1
[root@master hbase-1.3.1]$ bin/start-hbase.sh
在master、worker1、worker2中的任意一台机器使用bin/hbase shell 进入HBase自带的shell环境,然后使用命令version等,进行查看HBase信息及建立表等操作。
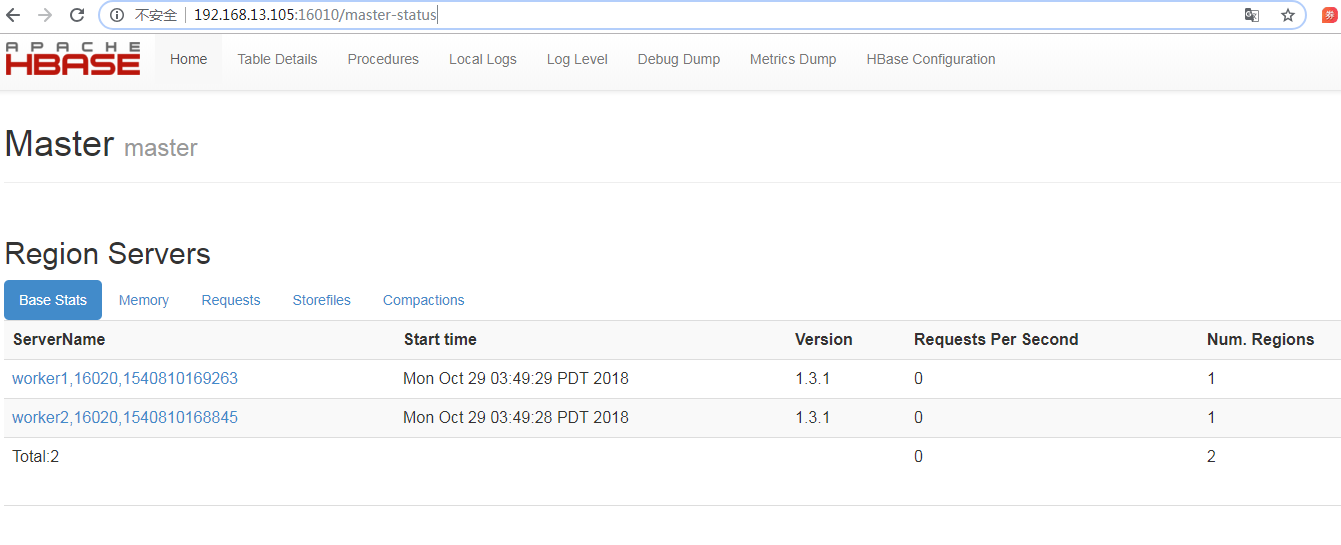
通过访问http://192.168.13.105:16010,出现以下界面,HBase集群搭建成功:
iServer使用HBase时,需要配置iServer所在电脑的hosts文件,添加HBase集群主机的IP和机器名。具体如下所示:
配置完成后,您可以通过iServer的数据注册功能将HBase关联至iServer中,作为分布式分析服务数据来源、数据存储位置等,还可将HBase作为服务来源,将其中的数据发布为地图服务和数据服务。