| 网络分析 |
SuperMap 交通网络分析提供以下主要分析功能:
以上分析功能及实现方法将分别在6.7-6.13各个小节中进行详细介绍。此外,SuperMap交通网络分析还提供了其他一些辅助分析的功能,如计算耗费矩阵、更新弧段权值、更新转向权值等将统一在6.14一节中进行介绍。
在深入了解交通网络分析的各个功能和使用方法之前,建议您首先对交通网络分析的流程进行了解。
交通网络分析的一般流程可以归纳如下:
1. 根据已有的数据,构建网络数据集,这是交通网络分析的首要步骤;
2. 设置交通网络分析环境,包括网络数据集及其拓扑关系字段、权值信息、转向表及转向权值信息、障碍信息以及交通规则等等;
3. 通过数据检查功能查找网络数据集和转向表的错误,根据错误信息对网络数据集或源数据进行修改,重复该步骤直至检查无误;
4. 加载交通网络模型;
5. 进行交通网络分析。分析前,需要设置交通网络分析参数,包括用于分析的点、障碍信息、权值信息、返回哪些分析结果等。其中,选址分区分析与其他分析功能不同,需要设置选址分区分析参数。
关于如何构建网络数据集,在第5章中已经进行了详细的介绍。对之后的各个步骤,将在下面的各个小节中分别进行介绍。
设置交通网络分析环境是通过设置交通网络分析(TransportationAnalyst)类的AnalystSetting属性实现的,我们需要为该属性设置一个TransportationAnalystSetting对象,该对象提供了交通网络分析所需要的参数的设置,这些参数包括:网络数据集及其拓扑关系字段(结点ID字段、弧段ID字段、起始结点ID字段和终止结点ID字段)、权值字段信息、转向表及转向权值信息、障碍信息以及交通规则等,这些参数的设置将直接影响到交通网络分析的结果。因此,交通网络分析环境设置实质上是对交通网络分析环境设置(TransportationAnalystSetting)类的属性进行设置,表 6.1列出了该类的各个属性及其含义。
表 6.1 TransportationAnalystSetting类的属性列表
类型 |
名称 |
描述 |
DatasetVector |
NetworkDataset |
获取或设置用于分析的网络数据集。必设。 |
String |
NodeIDField |
获取或设置网络数据集中标志结点 ID 的字段。必须正确设定标识结点 ID 的字段。仅支持 16 位整型、32 位整型字段。 |
String |
EdgeIDField |
获取或设置网络数据集中标志弧段 ID 的字段。必须正确设定标识弧段 ID 的字段。仅支持 16 位整型、32 位整型字段。 |
String |
FNodeIDField |
获取或设置网络数据集中标识弧段起始结点 ID 的字段。必须正确设定标识弧段起始结点 ID 的字段。仅支持 16 位整型、32 位整型字段。 |
String |
TNodeIDField |
获取或设置网络数据集中标志弧段终止结点 ID 的字段。必须正确设定标识弧段终止结点 ID 的字段。仅支持 16 位整型、32 位整型字段。 |
WeightFieldInfos |
WeightFieldInfos |
获取或设置权值字段信息集合对象。 |
Double |
Tolerance |
获取或设置点到弧段的距离容限。单位与 NetworkDataset 属性指定的网络数据集的单位相同。 |
Int32[] |
BarrierNodes |
获取或设置障碍结点的 ID 列表。可选。 |
Int32[] |
BarrierEdges |
获取或设置障碍弧段的 ID 列表。可选。 |
DatasetVector |
TurnDataset |
获取或设置转向表数据集。可选。 |
String |
TurnNodeIDField |
获取或设置转向结点 ID 的字段。仅支持 16 位整型、32 位整型字段。可选。 |
String |
TurnFEdgeIDField |
获取或设置转向起始弧段 ID 的字段。仅支持 16 位整型、32 位整型字段。可选。 |
String |
TurnTEdgeIDField |
获取或设置转向终止弧段 ID 的字段。仅支持 16 位整型、32 位整型字段。可选。 |
String[] |
TurnWeightFields |
获取或设置转向权值字段集合。可选。 |
String |
NodeNameField |
获取或设置存储结点名称的字段的字段名。可选。 |
String |
EdgeNameField |
获取或设置存储弧段名称的字段。可选。注意,如果不设置,即使将 IsPathGuidesReturn 属性设置为 true,分析结果中也不会返回行驶导引。 |
String |
RuleField |
获取或设置设置网络数据集中表示网络弧段的交通规则的字段。要求字段类型为文本型。可选。 |
String |
FTSingleWayRuleValues |
获取或设置用于表示正向单行线的字符串的数组。可选。 |
String |
TFSingleWayRuleValues |
获取或设置用于表示逆向单行线的字符串的数组。可选。 |
String |
ProhibitedWayRuleValues |
获取或设置用于表示禁行线的字符串的数组。可选。 |
String |
TwoWayRuleValues |
获取或设置用于表示双向通行线的字符串的数组。可选。 |
String |
EdgeFilter |
获取或设置交通网络分析中弧段过滤表达式。可选。 |
下面对交通网络分析环境的部分参数做进一步的说明。
网络数据集及其拓扑关系字段(NetworkDataset、NodeIDField、EdgeIDField、FNodeIDField、TNodeIDField)
网络数据集中表达其拓扑关系的字段包括:结点ID字段、弧段ID字段、弧段的起始结点ID字段和终止结点ID字段。必须指定用于分析的网络数据集及其拓扑关系字段,才能够保证网络的可用性,从而进一步完成交通网络分析。有关网络数据集及其拓扑关系字段的介绍,请参阅第5章。
TransportationAnalystSetting对象的NetworkDataset属性用于指定网络数据集,NodeIDField、EdgeIDField、FNodeIDField、TNodeIDField属性分别用于设置网络数据集中的结点 ID 字段、弧段 ID 字段、起始结点 ID 字段和终止结点 ID 字段。
弧段权值字段信息(WeightFieldInfos)
弧段权值是指通过该弧段的花费,分为正向权值和反向权值,从该弧段的起始结点到达终止结点的花费称为正向权值(或正向阻力),反之为反向权值(或反向阻力)。弧段权值需要从网络数据集的弧段属性表中指定两个字段,分别为正向权值字段和反向权值字段。弧段权值可以是任意类型,如经过该弧段所需的时间、该弧段的长度、该弧段一段时间内的平均拥堵情况、该弧段的交通事故率等。
在交通网络分析环境设置(TransportationAnalystSetting)类中,通过WeightFieldInfos属性来设置弧段权值,并且为该属性指定的是一个权值字段信息集合(WeightFieldInfos)对象,该对象是权值字段信息(WeightFieldInfo)对象的一个集合,其中的每一个WeightFieldInfo对象可以指定一对权值字段(正向权值字段和反向权值字段),并为此权值字段信息命名,该名称是该权值字段信息的唯一标识。表 6.2列出了WeightFieldInfo类的三个属性及其含义。
虽然在交通网络分析时只能使用一种弧段权值,但在分析环境中指定权值字段信息的集合的好处是:在分析环境设定多种权值,然后在分析时通过参数类指定具体使用哪种权值,这样就可以方便地变换弧段权值,而不需要重新设置交通网络分析环境。例如,分析从A到B的最佳路径,可以将弧段权值设置为道路的长度,分析结果就是最短路径;将弧段权值设置为通过该弧段花费的时间,那么分析结果就是时间最短的路径。由此也可见,弧段权值直接影响的分析结果的含义。
表 6.2 WeightFieldInfo类的属性列表
类型 |
名称 |
描述 |
String |
Name |
获取或设置权值字段信息的名称。 |
String |
FTWeightField |
获取或设置正向阻力字段。 |
String |
TFWeightField |
获取或设置反向阻力字段。 |
障碍结点、边(BarrierNodes、BarrierEdges)
障碍,顾名思义,是网络中不能通行的部分,可以是障碍边(也称障碍弧段)、障碍结点。在交通网络分析环境中,可以通过BarrierEdges属性将某些弧段设置为障碍边,通过BarrierNodes属性将若干结点设置为障碍点。一旦一条弧段被设置为障碍边,就表示这条边在分析过程中是禁行的。同样,一旦某结点被设置为障碍点,则分析时该结点是禁止通行的。
值得一提的是,障碍点和障碍边还可以在分析时在有关参数类中指定,并且它们与交通网络分析环境中指定的障碍是共同生效的。这在之后的小节中还会介绍。
点到弧段的距离容限(Tolerance)
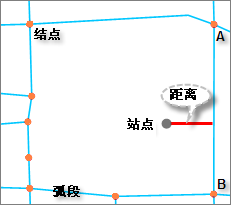
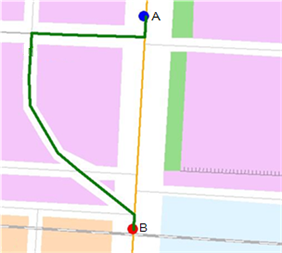
原则上,在交通网络分析中,可以指定网络中任意的点作为分析的经过点或障碍点,但应该在网络附近。如果这个点不在网络上(既不在弧段上也不在结点上),网络分析会根据该距离容限把该点归结到网络上,如图 6-1所示,桔色点代表网络结点,蓝色代表弧段,灰色点为站点,红色线段是站点到弧段 AB 的距离,如果该距离在设定的距离容限内,则把站点归结到弧段 AB 上。这个距离容限值通过Tolerance属性设置。
|
图 6-1 点到弧段的距离容限 |
设置合适的距离容限值才能保证网络分析的正常进行,如果设置得不合理,可能导致指定的点不能归结到网络上从而导致分析无结果或不正确。这里提供一种计算合理距离容限值的方法:
1. 计算出网络数据集中包含所有对象的最小外接矩形;
2. 计算出该矩形对象的高度及宽度;
3. 取两者中的较小值除以 40,得出较合适的距离容限。
交通规则(RuleField)
常用的交通规则包括:道路为正向单行线、逆向单行线、双向通行线或禁行线。其中,正向是指弧段上从起始结点到终止结点的方向,逆向则相反。RuleField属性用于指定网络数据集中代表交通规则的字段。该字段被要求是一个文本型字段,其字段值则是代表具体的交通规则的字符串。而何种字符串表示何种交通规则,则是通过设置FTSingleWayRuleValues、TFSingleWayRuleValues、ProhibitedWayRuleValues和TwoWayRuleValues四个属性来完成的。例如,通过FTSingleWayRuleValues属性可以设置代表正向单行线的字符串,并且允许设置多个不同的字符串,那么当交通规则字段的值是指定的这些字段时,对应的弧段则按照正向单行线处理。
转向表及转向权值字段集合(TurnDataset、TurnWeightFields)
转向表是一个纯属性表数据集。它记录了一个结点处各个转弯的花费。有关转向表的具体介绍请参阅第3章。另外,SuperMap提供了创建转向表的方法,即NetworkBuilder的CreateTurnTable方法。通过该方法可以创建网络数据集的所有结点或部分结点的转向表,该表包含了所有可能的转弯,但注意,该方法创建的转向表中转向权值字段的值均为0,需要使用者根据实际情况进行加工。
通过TurnDataset属性可以指定转向表,同时需要指定转向表中的转向结点 ID 字段、起始弧段 ID 字段和终止弧段 ID 字段,分别通过TurnNodeIDField、TurnFEdgeIDField和TurnTEdgeIDField属性设置。
与弧段权值相同,可以在转向表中创建多个字段,表示不同情形时的转向取值。类似地,可以通过TurnWeightFields属性设置多个转向权值字段。
弧段名称字段(EdgeNameField)
可以通过EdgeNameField属性指定网络数据集中代表弧段名称的字段。弧段名称用于在交通网络分析的路径分析的行驶导引中显示。如果不设置此字段,或者指定的字段不存在,分析结果中是不会包含行驶导引的,这一点需要非常注意。
弧段过滤表达式(EdgeFilter)
如果通过EdgeFilter属性设置了弧段过滤表达式,则只有符合表达式条件的弧段参与交通网络分析。当实际分析中不需要网络中所有的弧段参与时,可以设置过滤表达式从而只让符合条件的弧段参与分析,并且可能提高分析的性能。
第5章介绍了三个构建网络数据集的方法。其中,方法三由于完全按照点、线数据集已有的拓扑关系字段来构建网络,因此,如果这些字段存在错误,构建的网络数据集也会有误。而其他两种方式构建出的网络数据集理论上是不会存在错误的,因此,后期对网络数据集进行了修改,是最有可能的错误来源。
但无论何种原因导致的错误,都可能影响交通网络分析的结果。因此,SuperMap在TransportationAnalystSetting类提供了交通网络数据检查功能,即Check方法。该方法可以对交通网络数据集和对应的转向表进行检查。注意,该方法需要在设置交通网络分析环境,也就是设置了TransportationAnalyst类的AnalystSetting属性之后调用。
语法:
public TransportationAnalystCheckResult Check()
返回值说明:
交通网络分析数据检查结果。
该方法返回一个交通网络分析数据检查结果(TransportationAnalystCheckResult)对象,通过该对象的的 ArcErrorInfos 属性和 NodeErrorInfos 属性可以获取网络数据集的弧段错误信息和结点错误信息;通过 TurnErrorInfos 属性可以获取转向表的错误信息。以上三个属性的类型是字典(Dictionary),错误信息分别存储其中,键代表错误弧段或结点的 SMID,值代表错误类型。错误类型以数字表示,代表的具体错误含义如表 6.3和表 6.4所示。
表 6.3 网络数据集检查错误类型及说明
错误类型 |
说明 |
1 |
结点ID重复 检查网络数据集的子点数据集中,是否有与被检查结点具有相同结点ID的结点。如果有,则返回此类型错误,记录在结点错误数组中。 |
2 |
弧段ID重复 检查网络数据集的弧段数据集中,是否有与被检查弧段具有相同弧段ID的弧段。如果有,则返回此类型错误,记录在弧段错误数组中。 |
3 |
弧段没有对应结点 在网络数据集的弧段属性表中,每一条记录包含了该弧段的起、终结点ID。检查弧段数据集中的弧段,在子点数据集的属性表中是否存在与被检查弧段的起、终结点ID对应的结点。两结点任何一个不存在,则返回此类型错误,记录在弧段错误数组中。 |
4 |
空间位置不匹配 根据弧段数据集的属性表中弧段的起、终结点ID,检查该弧段与子点数据集中对应结点的空间位置是否正确。如不正确,则返回此类型错误,记录在弧段错误数组中。 例如,在弧段数据集的属性表中,弧段ID为1的弧段,其起、终结点ID分别为100、101,但在空间位置上,若结点100或结点101不在弧段1的起始或终止端点上,则属于此类型错误。 |
5 |
复杂线对象 网络数据集中存在复杂线对象,会导致拓扑错误。检查网络数据集中被检查弧段是否为复杂线对象。如果是,则返回此类型错误,记录在弧段错误数组中。 |
表 6.4 转向表检查错误类型及说明
错误类型 |
说明 |
1 |
结点找不到对应弧段 转向表记录了结点ID及对应的起始弧段和终止弧段ID。检查转向表中结点对应的弧段,在对应的网络数据集中是否存在。如果不存在,则返回此类型错误,记录在转向表错误数组中。 |
2 |
结点不在弧段上 检查转向表记录的结点与它的起始、终止弧段,在网络数据集中的空间位置关系是否正确(弧段与结点在弧段的端点处连接)。如果不正确,则返回此类型错误,记录在转向表错误数组中。 |
当设置好了交通网络分析环境,即设置了TransportationAnalyst类的AnalystSetting属性后,需要调用TransportationAnalyst类的Load方法,来加载交通网络模型。该过程将按照交通网络分析环境的设置,构建交通网络模型,存储于内存中。只有调用了该方法,所做的分析环境设置才会在交通网络分析的过程中生效。
语法:
public Boolean Load()
返回值说明:
加载成功返回true,失败返回false。
注意:
1. 如果对交通网络分析环境设置(TransportationAnalystSetting)进行了修改,或对网络数据集进行了修改,都需要重新调用Load方法加载网络模型,否则分析可能出错或结果不正确。
2. 如果没有修改交通网络分析环境或网络数据集,进行分析时不需要重复调用Load方法。如果需要再次调用Load方法,必须先使用Dispose方法释放资源,否则加载可能失败。
在进行最佳路径分析、最近设施查找分析、旅行商分析、多旅行商分析和服务区分析时,都使用了TransportationAnalystParameter类型的对象作为参数。选址分区使用单独的参数类LocationAnalystParameter进行参数设置,之后在介绍选址分区时再进行说明。
通过设置TransportationAnalystParameter对象的属性,为相应的交通网络分析功能提供参数,包括分析途径的点或结点、障碍边、障碍点、权值字段信息的名字标识、转向权值字段,以及分析结果是否返回途经结点集合,途经弧段集合,路由对象集合以及行驶导引等。下面详细介绍TransportationAnalystParameter类的属性,如表 6.5所示:
表 6.5 TransportationAnalystParameter类的属性列表
类型 |
名称 |
描述 |
Int32[] |
Nodes |
获取或设置分析时途经结点 ID 的集合。必设,但与 Points 属性互斥。如果同时设置,则只有分析前最后的设置有效。例如,先指定了结点集合,又指定了坐标点集合,然后分析,此时只对坐标点进行分析。 |
Point2Ds |
Points |
获取或设置分析时途经点的集合。必设,但与 Nodes 属性互斥。如果同时设置,则只有分析前最后的设置有效。例如,先指定了结点集合,又指定了坐标点集合,然后分析,此时只对坐标点进行分析。 |
String |
WeightName |
获取或设置权值字段信息的名称。即交通网络分析环境设置(TransportationAnalystSetting)中的权值字段信息集合(WeightFieldInfos)中的某一个权值字段信息对象(WeightFieldInfo)的 Name 属性的值。分析时,如果未设置,则默认使用权值字段信息集合中的第一个权值字段信息对象的名称。 |
String |
TurnWeightName |
获取或设置转向权值字段。可选。 即交通网络分析环境(TransportationAnalystSetting)中设置的转向权值字段集合(TurnWeightFields)中的一个值。 |
Int32[] |
BarrierEdges |
获取或设置障碍弧段 ID 列表。可选。 |
Int32[] |
BarrierNodes |
获取或设置障碍结点 ID 列表。可选。 |
Point2Ds |
BarrierPoints |
获取或设置障碍点列表。可选。 |
Boolean |
IsEdgesReturn |
获取或设置分析结果中是否包含途经弧段集合。设置为 true,在分析成功后,可以从 TransportationAnalystResult 对象的 Edges 属性获取途经弧段数组;为 false 则获取到的是一个空的数组。默认值为 false。 |
Boolean |
IsNodesReturn |
获取或设置分析结果中是否包含分析途经的结点集合。设置为 true,在分析成功后,可以从 TransportationAnalystResult 对象的 Nodes 属性获取途经结点集合;为 false 则获取到的是一个空的数组。默认值为 false。 |
Boolean |
IsPathGuidesReturn |
获取或设置分析结果中是否包含行驶导引集合。设置为 true,在分析成功后,可以从 TransportationAnalystResult 对象的 PathGuides 属性获取行驶导引集合;为 false 则获取到的是一个空的数组。默认值为 false。 |
Boolean |
IsRoutesReturn |
获取或设置分析结果中是否包含路由对象的集合(即 GeoLineM 的集合)。设置为 true,在分析成功后,可以从 TransportationAnalystResult 对象的 Routes 属性获取路由集合;为 false 则获取到的是一个空的数组。默认值为 false。 |
Boolean |
IsStopIndexesReturn |
获取或设置分析结果中是否要包含站点索引的集合。设置为 true,在分析成功后,可以从 TransportationAnalystResult 对象的 StopIndexes 属性获取站点索引集合;为 false 则获取到的是一个空的数组。默认值为 false。 |
结点模式与坐标点模式(Nodes、Points)
结点模式是指分析点为结点,用户需要指定对应结点的结点ID;坐标点模式是指分析点为坐标点,用户可以指定对应的坐标点。最佳路径分析、最近设施查找分析、旅行商分析、多旅行商分析和服务区分析均支持这两种模式,但需要注意并非分析中所使用的点都通过Nodes或Points指定,不同的分析功能需要在TransportationAnalystParameter指定的分析点有所不同,具体在介绍相应的分析功能时会进行说明。
特别需要强调的是,这两种模式是互斥的,原则上不要同时设置。如果同时进行设置,那么会以分析前的最后一个设置为准。例如,先使用Nodes属性指定了结点集合,又使用Points属性指定了坐标点集合,然后分析,此时只对坐标点进行分析。
障碍(BarrierNodes、BarrierEdges、BarrierPoints)
BarrierNodes、BarrierEdges、BarrierPoints三个属性分别用于指定障碍结点、障碍弧段和障碍点。在设置交通网络分析时,也可以指定障碍结点和障碍弧段,在分析时,这两处所指定的障碍结点和障碍弧段是共同生效的。
这里需要说明是障碍点。与障碍结点和障碍弧段不同,障碍点可以不在网络上(既不在弧段上也不在结点上),因此分析时需要根据距离容限(Tolerance)把障碍点归结到最近的网络上。距离容限是在交通网络分析环境中设置的,具体请参阅6.3小节。目前支持对最佳路径分析、最近设施查找、旅行商分析和物流配送分析设置障碍点。
是否返回行驶导引(IsPathGuidesReturn)
首先来了解什么是行驶导引(PathGuide):
行驶导引记录了最佳路径分析、最近设施查找、旅行商分析和多旅行商分析等常用交通网络分析(TransportationAnalyst)结果中的路径信息。一个行驶导引对象对应着一条从起点到终点的行驶路线。行驶导引由行驶导引子项(PathGuideItem)构成。行驶导引由行驶路线的一些关键要素构成,包括站点(即用户输入的用于分析的点,可以为普通的点坐标或者结点)、一般网络结点(如某个道路交叉口)和网络模型上的弧段(如某某路)等,这些关键要素的信息(如长度、方向等)就是由行驶导引子项来描述的。也可以说行驶导引子项就是行驶路线上的关键要素。
行驶导引子项可以概括为以下五类:
1. 站点:即用户选择的用于分析的点,如进行最佳路径分析时指定的要经过的各个点。
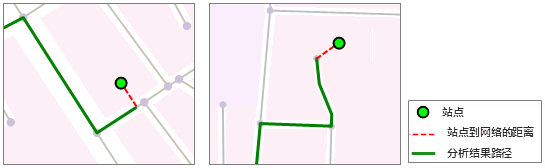
2. 站点到网络的线段:当站点为普通的坐标点时,需要首先将站点归结到网络上,才能基于网络进行分析。请参见 TransportationAnalystSetting 类的 Tolerance 属性的介绍。
如下图所示,红色虚线即为站点到网络的最短直线距离。注意,当站点在网络弧段的边缘附近时,如右图所示,这段距离是指站点与弧段端点的连线距离。
3. 站点在网络上的对应点:与“站点到网络的线段”对应,这个点就是将站点(普通坐标点)归结到网络上时,网络上相应的点。上面左图所示的情形,这个点就是站点在对应弧段上的垂足点;上面右图所示的情形,这个点则为弧段的端点。
4. 路段:也就是行驶经过的一段道路。交通网络中用弧段模拟道路,因此行驶路段都位于弧段上。注意,多个弧段可能被合并为一个行驶导引子项,合 并的条件是它们的弧段名称相同,并且相邻弧段间的转角小于 30 度。需要强调,到达站点前的最后一个行驶路段和到达站点后的第一个行驶路段,仅包含一条弧段或弧段的一部分,即使满足上述条件也不会与相邻弧段合并为一个 行驶导引。
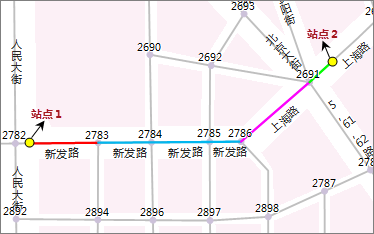
如下图所示,使用不同的颜色标示出了两个站点之间的行驶路段。其中,站点 1 之后的第一条路段(红色),虽然其所在弧段的名称与后面几条弧段的名称相同,且转向角度都小于 30 度,但由于它是站点后的第一条路段,因此并未将它们合并。而蓝色路段所覆盖的三条弧段,由于弧段名称相同且转角小于 30 度,故将它们合并为一个行驶导引子项;粉色路段由于与之前的路段具有不同的弧段名称,故成为另一个行驶导引子项;绿色路段由于是到达站点前的最后一条路 段,因此也单独作为一个行驶导引子项。
5. 转向点:两个相邻的行驶路段之间的路口。路口是指有可能发生方向改变的实际道路的路口(如十字路口或丁字路口)。在转向点处行驶方向可能发生改变。如上图中的结点 2783、2786 和 2691 都是转向点。转向点一定是网络结点。
通过行驶导引子项对象,可以获取路径中关键要素的 ID、名称、序号、权值、长度,还可以判断是弧段还是站点,以及行驶方向、转弯方向、花费等信息。按照行驶导引子项的序号对其存储的关键要素信息进行提取并组织,就可以描绘出如何从路径起点到达终点。表 6.6列出了PathGuideItem类的各个属性。
表 6.6 PathGuideItme类的属性列表
类型 |
名称 |
描述 |
Int32 |
ID |
获取该行驶导引子项的 ID。 除以下三种情形外,该值均为 -1: 当行驶导引子项为结点模式下的站点时,站点为结点,该值为该结点的结点 ID; 当行驶导引子项为转向点时,转向点为结点,该值为该结点的结点 ID; 当行驶导引子项为路段时,该值为路段对应的弧段的弧段 ID。如果该路段由多条弧段合并而成,则返回第一条弧段的 ID。 |
Boolean |
IsEdge |
获取该行驶导引子项是线还是点类型。 若为 true,表示为线类型,如站点到网络的线段、路段;若为 false,表示为点类型,如站点、转向点或站点被归结到网络上的对应点。 |
Boolean |
IsStop |
获取该行驶导引子项是否为站点,或站点被归结到网络上的对应点。 当 IsStop 为 true 时,对应的行驶导引子项可能是站点,或当站点为坐标点时,被归结到网络上的对应点。 |
String |
Name |
获取该行驶导引子项的名称。 除以下两种情形外,该值均为空字符串: 当行驶导引子项为站点(结点模式)或转向点时,该值根据交通网络分析环境中指定的结点名称字段(NodeNameField)的值给出,如未设置则为空字符串; 当行驶导引子项为路段或站点到网络的线段时,该值根据交通网络分析环境中指定的结点名称字段(EdgeNameField)的值给出,如未设置则为空字符串。 |
Double |
Length |
获取该行驶导引子项为线类型(即 IsEdge 为 true})时,对应线段的长度。单位与用于分析的网络数据集的单位相同。 仅当 IsEdge 为 true 时,也就是行驶导引子项为路段或站点到网络的线段时,Length 有意义,否则均为 0.0。 |
GeoLine |
GuideLine |
获取该行驶导引子项为线类型(即 IsEdge 为 true)时,对应的行驶导引线段。 当 IsEdge 为 false 时,该值为 null。 |
Rectangle2D |
Bounds |
获取该行驶导引子项的范围。仅当行驶导引子项为线类型(即 IsEdge 为 true)时,为线的最小外接矩形;为点类型(即 IsEdge 为 false)时,则为点本身。 |
DirectionType |
DirectionType |
获取该行驶导引子项的行驶方向,仅当行驶导引子项为线类型(即 IsEdge 为 true)时有意义,可以为东、南、西、北。 当 IsEdge 为 false 时,该值为 None,即无方向。 |
SideType |
SideType |
获取该行驶导引子项为站点时,站点在道路的左侧、右侧还是在路上。 当行驶导引子项为站点以外的类型时,该值为 None。 |
Double |
TurnType |
获取该行驶导引子项为点类型(即 IsEdge 为 false)时,该点处下一步行进的转弯方向。 |
TurnType |
TurnAngle |
获取该行驶导引子项为点类型(即 IsEdge 为 false)时,该点处下一步行进的转弯角度。单位为度,精确到 0.1 度。 当 IsEdge 为 true 时,该值为 -1。 |
Double |
Distance |
获取站点到网络的距离,仅当行驶导引子项为站点时有效。单位与用于分析的网络数据集的单位相同。 站点可能不在网络上(既不在弧段上也不在结点上),必须将站点归结到网络上,才能基于网络进行分析。该距离是指站点到最近一条弧段的距离。可参阅 TransportationAnalystSetting 的 Tolerance 属性的介绍。 |
Int32 |
Index |
获取该行驶导引子项的序号。 除以下两种情形外,该值均为 -1: 当行驶导引子项为站点时,该值为该站点在所有站点中的序号,从 1 开始。例如某个站点是行驶路线经过的第 2 个站点,则此站点的 Index 值为 2; 当行驶导引子项为转向点时,该值为该点距离上一个转向点或站点的路口数。例如某个转向点之前的两个路口是最近的一个站点,则这个转向点的 Index 值为 2;当某个点同时为站点和转向点时,Index 为在整个行驶过程的所有站点中该站点的位置。 |
Double |
Weight |
获取该行驶导引子项的权值,即行使导引对象子项的花费。单位与交通网络分析参数(TransportationAnalystParameter)对象的 WeightName 属性所指定的权值字段信息(WeightFieldInfo)对象的权值字段的单位相同。 当行驶导引子项为路段、转向点或结点模式下的站点时,得到的花费才有意义,否则均为 0.0。 当行驶导引子项为路段时,根据弧段权值和转向权值计算得出相应的花费。如果未设置转向表,则转向权值为 0; 当行驶导引子项为转向点或结点模式下的站点时(二者均为结点),为相应的转向权值。如果未设置转向表,则为 0.0。 |
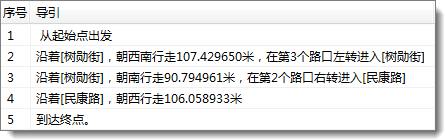
下面通过一个例子,来直观地了解行驶导引子项与行驶导引。
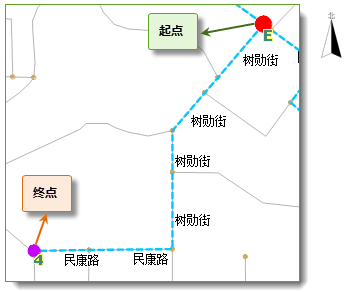
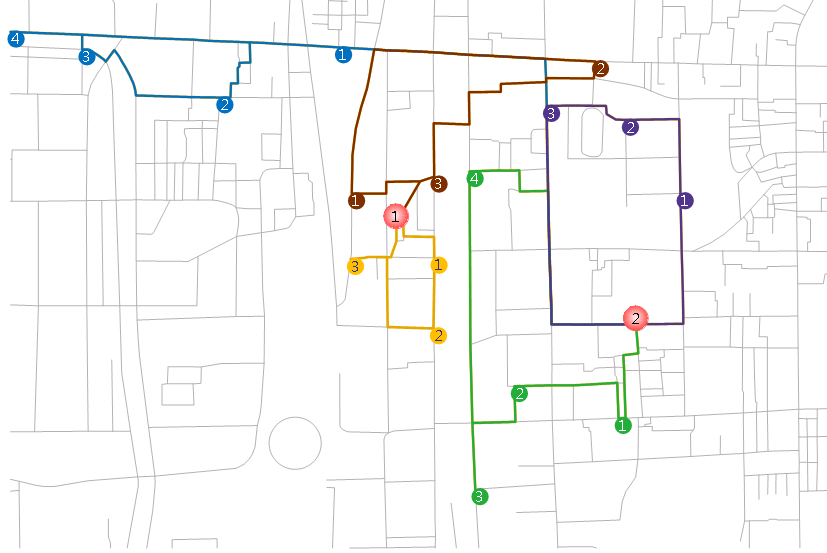
图 6-2中的蓝色虚线为最近设施查找分析的结果中的一条路径,在最近设施查找的返回结果中,可以获得这条路径对应的行驶导引。这条路径共包含7个行驶导引子项,包括2个站点(起点和终点)、3个弧段(即路段)和2个结点(即路口)。
|
图 6-2 最佳路径分析 |
下表列出了上图所示的路径所包含的7个行驶导引子项的信息,包括是否为站点、是否为弧段、序号、行驶方向、转弯方向、弧段名称等。注意,这里并未列出行驶导引子项包含的所有信息,如转弯角度、花费、站点到弧段的距离等,用户可根据实际需要决定是否需要这些信息。
ID |
IsStop |
IsEdge |
Index |
Length |
Name |
DirectionType |
TurnType |
0 |
true |
false |
1 |
0.0 |
—— |
None |
Ahead |
1 |
false |
true |
-1 |
107.42965 |
树勋街 |
South |
None |
2 |
false |
false |
3 |
0.0 |
—— |
None |
Left |
3 |
false |
true |
-1 |
90.79496 |
树勋街 |
South |
None |
4 |
false |
false |
2 |
89.222265 |
—— |
None |
Right |
5 |
false |
true |
-1 |
106.05893 |
民康路 |
West |
None |
6 |
true |
false |
2 |
0.0 |
—— |
None |
End |
按照上面的表格将行驶导引子项记录的信息加以组织,可以得到如下所示的该路径的导引描述:
|
图 对行驶导引子项的信息加以组织得到的行驶导引 |
这里需要特别注意,如果没有在TransportationAnalystSetting中指定弧段名称字段,或指定的字段不存在,则即使将IsPathGuidesReturn设置为true,分析结果中也不会返回行驶导引,因为无法给出道路(即弧段)的名称,就不能够起到引导作用。
以上是进行交通网络分析之前普遍要操作的内容,尤其是交通网络分析环境设置是所有交通网络分析功能实现的前提,下面就具体介绍各个交通网络分析功能的实现过程以及介绍相关的概念。
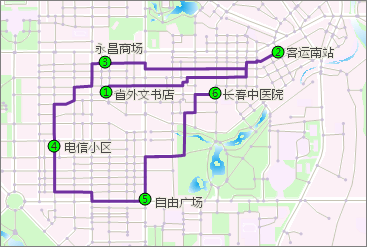
最佳路径分析,是指在网络上选择N(N大于等于2)个点(称为途经点),求解按照途经点的选择顺序,依次经过这些点的花费最小的路径。“花费最小”有多种理解,如基于单因素考虑的时间最短、费用最低、风景最好、路况最佳、过桥最少、收费站最少、经过乡村最多等。图 6-3展示了最佳路径分析的一个实例。
|
图 6-3 最佳路径分析 |
必须按照途经点的给定顺序访问途经点是最佳路径分析的重要特征。最佳路径分析可以理解为按照途经点的给定次序,依次查找两点间的最佳路径,最后加和。例如,要顺序访问1、2、3、4四个结点,则需要分别找到1、2结点间的最佳路径R1_2,2、3间的最佳路径R2_3和3、4结点间的最佳路径R3_4,顺序访问1、2、3、4四个结点的最佳路径R= R1_2 + R2_3 + R3_4。
TransportationAnalyst类的FindPath方法,用于实现最佳路径分析。按照交通网络分析的步骤,在加载网络模型之后,就可以调用该方法进行最佳路径分析了。
语法:
public TransportationAnalystResult FindPath(TransportationAnalystParameter parameter,Boolean hasLeastEdgeCount)
参数说明:
parameter:指定的交通网络分析参数。
hasLeastEdgeCount:指定是否按照弧段数最少查找。true 表示按照弧段数最少进行查询。
返回值说明:
分析结果对象。
进行最佳路径分析的N个途经点,是在TransportationAnalystParameter类型的参数parameter中指定的。可以选择结点模式,即通TransportationAnalystParameter对象的Nodes属性指定途经结点集合,或者坐标点模式,即使用Points属性指定途经坐标点集合,分析时的访问次序就是指定的途经点在集合中的次序。但注意,二者互斥,详细规则以及其他参数的说明请参阅6.6小节。
将方法中的hasLeastEdgeCount参数设置为true,则按照弧段数最小来查找最佳路径。由于弧段数少不代表弧段的权值小,所以此时查出的结果可能不是最小耗费路径。如图 6-4所示,如果连接 AB 的绿色路径的弧段数少于黄色路径,当该参数设置为 true 时,绿色路径就是查询得到的路径,设置为 false 时,黄色路径就是查询得到的路径。
|
图 6-4 是否按照弧段数最少进行分析 |
最佳路径分析、最近设施查找分析、旅行商分析、多旅行商分析的结果均通过一个交通网络分析结果(TransportationAnalystResult)对象返回,通过该对象的属性可以获得途经结点集合、途经弧段集合、路由集合、行驶导引、权值数组等分析结果。表 6.7列出TransportationAnalystResult类的各个属性。
表 6.7 TransportationAnalystResult类的属性列表
类型 |
名称 |
描述 |
Int32[][] |
Nodes |
获取分析结果的途经结点集合。注意,必须将 TransportationAnalystParameter 对象的 IsNodesReturn 设置为 true,分析结果中才会包含途经结点集合,否则为一个空的数组。 |
Int32[][] |
Edges |
获取分析结果的途经弧段集合。注意,必须将 TransportationAnalystParameter 对象的 IsEdgesReturn 设置为 true,分析结果中才会包含途经弧段集合,否则为一个空的数组。 |
GeoLineM[] |
Routes |
获取分析结果的路由对象集合(GeoLineM 的集合)。注意,必须将 TransportationAnalystParameter 对象的 IsRoutesReturn 设置为 true,分析结果中才会包含路由集合,否则为一个空的数组。 |
PathGuide[] |
PathGuides |
获取行驶导引集合。注意,必须将 TransportationAnalystParameter 对象的 IsPathGuidesReturn 设置为 true,分析结果中才会包含行驶导引集合,否则为一个空的数组。
|
Int32[][] |
StopIndexes |
获取站点索引的二维数组,该数组反映了站点在分析后的排列顺序。注意,必须将 TransportationAnalystParameter 对象的 IsStopIndexesReturn 设置为 true,分析结果中才会包含站点索引集合,否则为一个空的数组。 |
Double[] |
Weights |
获取代表花费的权值数组。单位与交通网络分析参数(TransportationAnalystParameter)对象的 WeightName 属性所指定的权值字段信息(WeightFieldInfo)对象的权值字段的单位相同。
|
Double[][] |
StopsWeights |
获取根据站点索引对站点排序后,站点间的花费(权值)。单位与交通网络分析参数(TransportationAnalystParameter)对象的 WeightName 属性所指定的权值字段信息(WeightFieldInfo)对象的权值字段的单位相同。 |
以上是对TransportationAnalystResult的属性的基本介绍,下面针对最佳路径分析,着重介绍以下属性的具体含义:
途经弧段集合(Edges):由于分析结果只有一条路径,因此数组的一维长度为 1,二维元素为该路径途经弧段的弧段 ID。
途经结点集合(Nodes):由于只有一条结果路径,因此数组的一维长度为 1,二维元素为该路径途经结点的结点 ID。
路由对象集合(Routes):永远只有一条结果路由。
权值数组(Weights):因为只有一条路径,所以只有一个值,即该路径的总花费。
站点索引(StopIndexes):结果路径只有一条,故数组的一维长度为 1,二维元素表示结果路径经过站点的次序:
1. 结点模式:如设置的分析结点 ID 为 1,3,5 的三个结点,因为结果途经顺序必须为 1,3,5,所以二维元素值依次为 0,1,2,即结果途经顺序在初始设置结点串中的索引。
2. 坐标点模式:如设置的分析坐标点为 Pnt1,Pnt2,Pnt3,因为结果途经顺序必须为 Pnt1,Pnt2,Pnt3,所以二维元素值依次为 0,1,2,即结果途经坐标点顺序在初始设置坐标点串中的索引。
站点权值(StopWeights):由于结果路径只有一条,故数组的一维长度为 1。假设指定经过点 1、2、3,则二维元素依次为:1 到 2 的耗费、2 到 3 的耗费。
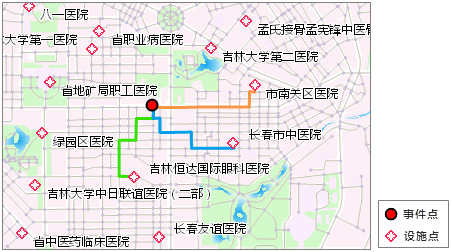
最近设施分析是指在网络上给定一个事件点和一组设施点,为事件点查找以最小耗费能到达的一个或几个设施点,结果为从事件点到设施点(或从设施点到事件点)的最佳路径。
设施点和事件点是最近设施查找分析的基本要素。设施点是提供服务的设施,如学校、超市、加油站等;事件点则是需要设施点的服务的事件位置。
例如,在某位置发生一起交通事故,要求查找在 10 分钟内最快到达的 3 家医院,超过 10 分钟能到达的都不予考虑。此例中,事故发生地即是一个事件点,周边的医院则是设施点。分析的结果如图 6-5所示,会给出从事故点能够最快到达的3家医院的路径。并且,最近设施查找实际上也是一种路径分析,因此,同样可以应用障碍边和障碍点的设置,在行驶路途上这些障碍将不能被穿越,在路径分析中会予以考虑。
|
图 6-5 最近设施查找分析 |
按照交通网络分析的步骤,在加载网络模型之后,就可以调用对应的方法进行最近设施查找分析了。TransportationAnalyst类的提供了两个重载方法FindClosestFacility,用于实现最佳路径分析。
方法一:根据指定的参数进行最近设施查找分析,事件点为结点 ID。
语法:
public TransportationAnalystResult FindClosestFacility(TransportationAnalystParameter parameter,Int32 eventID, Int32 facilityCount, Boolean isFromEvent, double maxWeight)
参数说明:
parameter:指定的交通网络分析参数。
eventID:指定的作为事件点的结点 ID。
facilityCount:指定的要查找的设施点数量。
isFromEvent:指定是否从事件点到设施点进行查找。指定为 true,表示从事件点到设施点进行查找;false 表示从设施点到事件点进行查找。
maxWeight:指定的查找半径。单位同网络分析环境中设置的权值字段。设为0表示查找整个网络。
返回值说明:
分析结果对象。
方法二:根据指定的参数进行最近设施查找分析,事件点为坐标点。
语法:
public TransportationAnalystResult FindClosestFacility(TransportationAnalystParameter parameter,Point2D eventPoint, Int32 facilityCount, Boolean isFromEvent, double maxWeight)
参数说明:
parameter:指定的交通网络分析参数。
eventPoint:指定的事件点的位置。
facilityCount:指定的要查找的设施点数量。
isFromEvent:指定是否从事件点到设施点进行查找。指定为 true,表示从事件点到设施点进行查找;false 表示从设施点到事件点进行查找。
maxWeight:指定的查找半径。单位同网络分析环境中设置的权值字段。设为0表示查找整个网络。
返回值说明:
分析结果对象。
事件点允许为坐标点或结点ID,分别通过以上两个方法的eventID或eventPoint参数指定,而设施点则是在 TransportationAnalystParameter 类型的参数 parameter 中指定的。同样,设施点的指定方式也有两种:结点模式、坐标点模式,即通过TransportationAnalystParameter对象的Nodes属性,可以指定作为分析点的结点的结点ID集合,称为结点模式;通过Points属性,指定作为分析点所在位置的坐标点集合,这是坐标点模式。详见6.6小节。
除设施点外,通过TransportationAnalystParameter对象还可以设置其他一些用于分析的参数,具体内容参阅6.6小节。
最近设施查找分析的结果信息都保存在TransportationAnalystResult类对象的相关属性中,关于这些属性的基本介绍,请参阅6.6小节。这里针对最近设施查找商分析,着重介绍以下属性的具体含义:
途经弧段集合(Edges):由于分析结果中路径的数量与查找到的最近设施点的数目相同,因此数组的一维长度为结果设施点的个数,二维元素为该路径途经弧段的弧段 ID。
途经结点集合(Nodes):由于分析结果中路径的数量与查找到的最近设施点的数目相同,因此数组的一维长度为结果设施点的个数,二维元素为各条路径途经结点的结点 ID。
路由对象集合(Routes):查找到的设施个数就是结果路由的数量。
权值数组(Weights):权重值的个数与结果设施点的个数相同,每个元素代表从事件点到达该设施点的路径的总花费。
站点索引(StopIndexes):无效属性。
站点权值(StopWeights):无效属性。
旅行商分析是查找经过指定一系列点的路径,旅行商分析是无序的路径分析。旅行商可以自己决定访问结点的顺序,目标是旅行路线阻抗总和最小(或接近最小)。
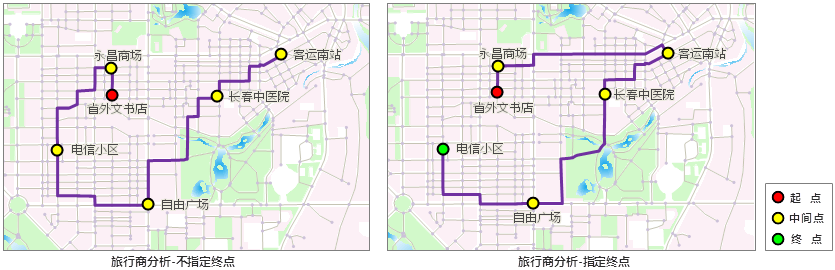
SuperMap的旅行商分析,默认给定的旅行商经过点集合中的第一个点作为旅行商的起点,此外,用户还可以指定终点,如果选择指定终点,则给定的经过点集合的最后一个点为终点,此时,旅行商从第一个点出发,到指定的终点结束,而其他经过点的访问次序由旅行商自己决定。如果不指定终点,则旅行商从起点出发,而其他点的访问次序由旅行商决定,即按照总花费最小的原则决定访问顺序。图 6-6为不指定终点和指定终点时旅行商分析的实例。
|
图 6-6 不指定终点和指定终点时的旅行商分析 |
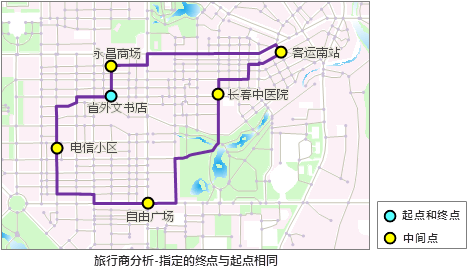
另外,如果选择指定终点,终点可以与起点相同,即经过点集合中的最后一个点与第一个点相同。此时,旅行商分析的结果是一条闭合路径,即从起点出发,最终回到该点,如图 6-7所示:
|
图 6-7 指定终点与起点相同时的旅行商分析 |
需要注意,最佳路径分析(FindPath 方法)与旅行商分析类似,都是在网络中寻找遍历所有经过点的花费最少的路径。但二者具有明显的区别,即在遍历所有经过点时,二者对访问经过点的顺序处理有所不同:最佳路径分析必须按照给定的经过点的次序访问所有点,而旅行商分析需要确定最优次序来访问所有点,而并不一定按照指定的经过点的次序。
按照交通网络分析的步骤,在加载网络模型之后,就可以调用TransportationAnalyst类的FindTSPPath方法进行旅行商分析了。
语法:
public TransportationAnalystResult FindTSPPath(TransportationAnalystParameter parameter, Boolean isEndNodeAssigned)
参数说明:
parameter:指定的交通网络分析参数。
isEndNodeAssigned:指定是否指定终点。指定为 true 表示指定终点,此时给定的经过点集合中最后一个点即为终点;否则不指定终点。
返回值说明:
分析结果对象。
通过TransportationAnalystParameter类型的parameter参数,可以指定旅行商分析所需的各个参数。旅行商分析的经过点的指定方式有两种:结点模式、坐标点模式,即通过TransportationAnalystParameter对象的Nodes属性,可以指定作为分析点的结点的结点ID集合,称为结点模式;通过Points属性,指定作为分析点所在位置的坐标点集合,这是坐标点模式。详见6.6小节。
通过TransportationAnalystParameter对象的属性还可以设置其他用于分析的参数信息,具体内容请参阅读6.6小节。
旅行商分析的结果信息都保存在TransportationAnalystResult类对象的相关属性中,关于这些属性的基本介绍,请参阅6.6小节。这里针对旅行商分析,着重介绍以下属性的具体含义:
途经弧段集合(Edges):由于分析结果只有一条路径,因此数组的一维长度为 1,二维元素为该路径途经弧段的弧段 ID。
途经结点集合(Nodes):由于只有一条结果路径,因此数组的一维长度为 1,二维元素为该路径途经结点的结点 ID。
路由对象集合(Routes):永远只有一条结果路由。
权值数组(Weights):因为只有一条路径,所以只有一个值,即该路径的总花费。
站点索引(StopIndexes):结果路径只有一条,故数组的一维长度为 1,二维元素表示结果路径经过站点的次序:
1. 结点模式:如设置的分析结点 ID 为 1,3,5 的三个结点,而结果途经顺序为 3,5,1,则二维元素值依次为 1,2,0,即结果途经顺序在初始设置结点串中的索引。
2. 坐标点模式:如设置的分析坐标点为 Pnt1,Pnt2,Pnt3,而结果途经顺序为 Pnt2,Pnt3,Pnt1,则二维元素值依次为 1,2,0,即结果途经坐标点顺序在初始设置坐标点串中的索引。
站点权值(StopWeights):由于结果路径只有一条,故数组的一维长度为 1。假设指定经过点 1、2、3,分析结果中站点索引为 1、0、2,则二维元素依次为:2 到 1 的耗费、1 到 3 的耗费。
多旅行商分析也称为物流配送,是指在网络数据集中,给定 M 个配送中心点和 N 个配送目的地(M,N 为大于零的整数),查找经济有效的配送路径,并给出相应的行走路线。如何合理分配配送次序和送货路线,使配送总花费达到最小或每个配送中心的花费达到最小,是物流配送所解决的问题。
多旅行商分析的结果将给出每个配送中心所负责的配送目的地,以及这些配送目的地的经过顺序,和相应的行走路线,从而使该配送中心的配送花费最少,或者使得所有的配送中心的总花费最小。并且,配送中心点在完成其所负责的配送目的地的配送任务后,最终会回到配送中心点。
例如,某地区现有 50 个报刊零售地(配送目的地),4 个报刊供应地(配送中心),现寻求这 4 个供应地向报刊零售地发送报纸的最优路线,属物流配送问题。
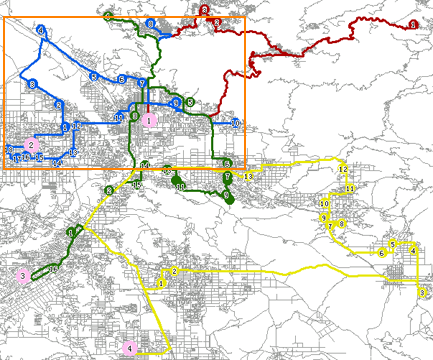
图 6-8为报刊配送的分析结果,其中红色大一点的圆点代表 4 个报刊供应地(配送中心),而其他小一点的圆点代表报刊零售地(配送目的地),每个配送中心的配送方案采用不同的颜色标示,包括它所负责的配送目的地、配送次序以及配送线路。
|
图 6-8 多旅行商分析的结果 |
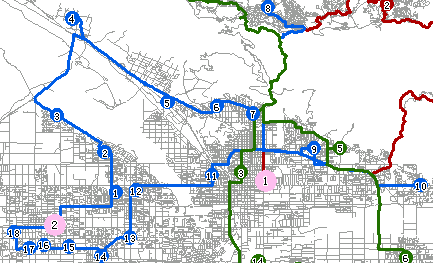
图 6-9为上图中矩形框圈出的第 2 号配送中心的配送方案。蓝色的标有数字的小圆点是2号配送中心所负责的配送目的地(共有 18 个),2 号配送中心将按照配送目的地上标有数字的顺序依次发送报纸,即先送 1 号报刊零售地,再送 2 号报刊零售地,依次类推,并且沿着分析得出的蓝色线路完成配送,最终回到配送中心。
|
图 6-9 多旅行商分析的结果 |
需要注意,由于物流配送的目的是寻找使配送总花费最小或每个配送中心的花费最小的方案,因此,分析结果中有可能某些物流配送中心点不参与配送。
按照交通网络分析的步骤,在加载网络模型之后,就可以调用对应的方法进行多旅行商分析了。TransportationAnalyst类的提供了两个重载方法FindMTSPPath ,用于实现多旅行商分析。
方法一:多旅行商(物流配送)分析,配送中心为结点 ID 数组。
语法:
public TransportationAnalystResult FindMTSPPath(TransportationAnalystParameter parameter,Int32[] centerNodes, Boolean hasLeastTotalCost)
参数说明:
parameter:指定的交通网络分析参数。
centerNodes:指定的作为配送中心的结点 ID 数组。
hasLeastTotalCost:指定配送模式是否为总花费最小方案。若为 true,则按照总花费最小的模式进行配送,此时可能会出现某些配送中心点配送的花费较多而其他的配送中心点的花费较少的情况。若为 false,则为局部最优,此方案会控制每个配送中心点的花费,使各个中心点花费相对平均,此时总花费不一定最小。
返回值说明:
分析结果对象。
方法二:多旅行商(物流配送)分析,配送中心为点坐标串。
语法:
public TransportationAnalystResult FindMTSPPath(TransportationAnalystParameter parameter,Int32[] centerNodes, Boolean hasLeastTotalCost)
参数说明:
parameter:指定的交通网络分析参数。
centerPoints:指定的作为配送中心的坐标点集合。
hasLeastTotalCost:指定配送模式是否为总花费最小方案。若为 true,则按照总花费最小的模式进行配送,此时可能会出现某些配送中心点配送的花费较多而其他的配送中心点的花费较少的情况。若为 false,则为局部最优,此方案会控制每个配送中心点的花费,使各个中心点花费相对平均,此时总花费不一定最小。
返回值说明:
分析结果对象。
多旅行商的配送中心可以指定为结点或坐标点。使用方法一,可以通过centerNodes参数指定配送中心所在结点的结点ID;使用方法二,则通过centerPoints参数指定配送中心所在的坐标点。
配送目的地则是在TransportationAnalystParameter类型的参数parameter中指定的。配送目的地的选择也分为结点模式和坐标点模式:即通过TransportationAnalystParameter对象的Nodes属性,可以指定作为配送目的地的结点的结点ID集合,称为结点模式;通过Points属性,指定配送目的地所在位置的坐标点集合,这是坐标点模式。两种模式互斥,详见6.6一节。
通过TransportationAnalystParameter对象的属性还可以设置其他用于分析的参数信息,具体内容请参阅读6.6小节。
多旅行商分析的结果信息都保存在TransportationAnalystResult类对象的相关属性中,关于这些属性的基本介绍,请参阅6.6小节。这里针对多旅行商分析,着重介绍以下属性的具体含义:
途经弧段集合(Edges):该二维数组的一维长度为参与配送的中心点数,每一个配送中心点对应一条路径;二维元素为各条路径途经弧段的弧段 ID。注意,配送模式为局部最优时,所有中心点参与配送,为总花费最小模式时,参与配送的中心点数可能少于指定的中心点数。
途经结点集合(Nodes):该二维数组的一维长度为参与配送的中心点数,每一个配送中心点对应一条路径;二维元素为各条路径途经结点的结点 ID。注意,配送模式为局部最优时,所有中心点参与配送,为总花费最小模式时,参与配送的中心点数量可能少于指定的中心点数。
路由对象集合(Routes):配送模式为局部最优时,有多少个配送中心就会有多少个结果路由,为总花费最小模式时,结果路由的个数可能会小于配送中心的个数。
权值数组(Weights):权值的个数与分析结果中所使用的配送中心的个数相同,元素的含义为对应中心点的配送路线的总花费。注意,配送模式为局部最优时,所有中心点参与配送,为总花费最小模式时,参与配送的中心点数可能少于指定的中心点数。
站点索引(StopIndexes):类似于旅行商分析,只不过数组的一维长度为参与配送的中心点数。二维元素的含义与旅行商分析相同,表示对应的中心点的配送路径经过站点的次序。注意,配送模式为局部最优时,所有中心点参与配送,为总花费最小模式时,参与配送的中心点数可能少于指定的中心点数。
站点权值(StopWeights):多旅行商分析的结果可能有多条路径,因此数组一维长度为路径的数量,二维元素为该路径所经过的站点的之间的耗费,需要注意的是,多旅行商分析的路径经过的站点是包括中心点的,且路径的起终点均是中心点。例如,一条结果路径是从中心点 1 出发,经过站点 2、3、4,对应的站点索引为 1、2、0,则站点权重依次为:1 到 3 的耗费、3 到 4 的耗费、4 到 2 的耗费和 2 到 1 的耗费。
服务区是以指定点为中心,在一定阻力范围内,包含所有可通达边、通达点的一个区域。服务区分析就是依据给定的阻力值(即服务半径)为网络上提供某种特定服务的位置(即中心点)查找其服务的范围(即服务区)的过程。阻力可以是到达的时间、距离或其他任何花费。例如:为网络上某点计算其 30 分钟的服务区,则结果服务区内,任意点出发到该点的时间都不会超过 30 分钟。
服务区分析也可以理解为不考虑中心资源供给量和需求量,而只考虑供给方与需求方之间网络弧段阻力的资源分配。这类分析一般可用于评估分析在某一位置邮局、医院、超市等公共设施一般的服务范围,从而为选择公共设施的最佳位置提供参考。
服务区分析的结果包含了每个服务中心点所能服务到的路由和区域。路由是指从服务中心点出发,按照阻力值不大于所指定的服务半径的原则,沿网络弧段延伸出的路径;服务区则是按照一定算法将路由包围起来所形成的面状区域。
图 6-10展示了服务区分析将要解决的问题以及结果会提供什么样的信息。红色圆点代表提供服务或资源的服务中心点,各种颜色的面状区域就是以相应的服务中心点为中心,在给定的阻力范围内的服务区,每个服务中心点所服务到的路由也以对应的颜色标示。
|
|
|
图 6‑10 服务区分析 |
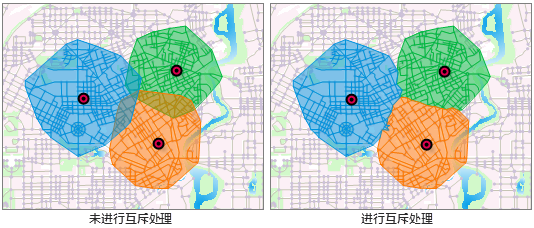
当服务半径足够大时,两个或多个相邻的服务区之间可能产生交叠,服务区所覆盖的路由也产生了交叠,此时,可以通过互斥处理,使服务区和路由均不产生交叠。如图 6-11所示,左图未进行互斥处理,右图进行了互斥处理。
|
|
|
图 6‑11 服务区互斥处理 |
服务区分析可以指定是否从中心点开始分析。从中心点开始分析和不中中心点开始分析,体现了服务中心和需要该服务的需求地的关系模式。
从中心点开始分析,是一个服务中心向服务需求地提供服务。例如,某个奶站向各个居民点送牛奶,如果要对这个奶站进行服务区分析,看这个奶站在允许的条件下所能服务的范围,那么在实际分析过程中就应当使用从中心点开始分析的模式;
而不从中心点开始分析,是一个服务需求地主动到服务中心获得服务。例如,如果想分析一个区域的某个学校在允许的条件下所能服务的区域时,在现实中,都是学生主动来到学校学习,接受学校提供的服务,那么在实际分析过程中就应当使用不从中心点开始分析的模式。
注意,从中心点出发和不从中心点,在分析时,由于弧段的正向权值和反向权值可能不同,结点的转向权值也可能不同,因此分析的结果也可能不同。
服务区分析有两种。有简单服务区分析和详细服务区分析。选择简单服务区,将构造能覆盖结果路由的凸面作为结果服务区面。选择详细服务区,生成的分析结果会严格按照结果路由生成面轮廓结果。相较于简单服务区,详细服务区更能准确的对服务区进行建模。
TransportationAnalyst类的FindServiceArea方法,用于实现服务区分析。下面对其进行介绍:
语法:
public ServiceAreaResult FindServiceArea(TransportationAnalystParameter parameter,double[] weights,Boolean isFromCenter,Boolean isCenterMutuallyExclusive)
参数说明:
parameter:指定的交通网络分析参数。
weights:指定的服务区半径数组。数组长度应与给定的服务中心点的数量一致,且数组元素按照顺序与中心点一一对应。服务区半径的单位与指定的权值信息中的正向、反向阻力字段的单位一致。
isFromCenter:指定是否从中心点开始分析。若为 true,则从中心点开始分析。若为 false,则不从中心点开始分析。
isCenterMutuallyExclusive:
返回值说明:
分析结果对象。
实现服务区分析时,服务中心的指定是在TransportationAnalystParameter类型的参数parameter中指定的,可以指定多个服务中心点。服务中心点的选择分为结点模式和坐标点模式:即通过TransportationAnalystParameter对象的Nodes属性,指定作为服务中心点的结点的结点ID集合,称为结点模式;通过Points属性,指定中心点所在位置的坐标点集合,这是坐标点模式。两种模式互斥,详见6.6一节。
在TransportationAnalystParameter类型的参数中还可以设置服务区分析需要的其他信息,具体介绍请参阅6.6一节。
ServiceAreaResult类继承自TransportationAnalystResult类,它继承了TransportationAnalystResult类的Nodes、Edges、Routes和Weights属性,而PathGuides、StopIndexes和StopWeights属性对服务区分析无效。除此,ServiceAreResult还提供了两个属性用于获得分析结果中的资源供给中心集合,如表 6.8所示。
表 6.8 SupplyCenter类的属性列表
类型 |
名称 |
描述 |
GeoRegion[] |
ServiceRegions |
获取分析结果的服务区面对象集合。数组元素的顺序与中心点的指定顺序一致。 |
Int32[] |
ServiceRouteCounts |
获取服务区分析结果中的每个服务区的 Route 个数的一个数组。数组元素的顺序与中心点的指定顺序一致。 |
有关Nodes、Edges、Routes和Weights属性的基本信息,请参阅6.6小节。这里针对服务区分析,着重介绍以下属性的具体含义:
途经弧段集合(Edges):该二维数组的一维长度为服务区中心点数,二维元素为每个中心点的服务区所覆盖(包括部分覆盖)的弧段的弧段ID。
途经结点集合(Nodes):该二维数组的一维长度为服务中心点数,二维元素为每个中心点的服务区所覆盖的结点的结点 ID。
路由对象集合(Routes):该数组存储了按照中心点的指定顺序,每个服务区所覆盖(包括部分覆盖)的路由。从服务区分析结果的 ServiceRouteCounts 属性获取的数组的元素顺序对应了中心点的指定顺序,元素值为该中心点的服务区所覆盖(包括部分覆盖)的路由的数量,结合该数组,可以得知每个服务区对应的路由有哪些。
权值数组(Weights):该数组存储了按照中心点的指定顺序,每个服务区的总耗费,也就是服务区所覆盖的所有路由的权值。
选址分区分析是为了确定一个或多个待建设施的最佳位置,使得设施可以用一种最经济有效的方式为需求方提供服务或者商品。选址分区不仅仅是一个选址过程,还要将需求点的需求分配到相应的新建设施的服务区中,因此称之为选址与分区。
首先来了解选址分区的有关概念:
资源供给中心:即中心点,是提供资源和服务的设施,对应于网络结点,资源供给中心的相关信息包括最大阻力值、资源供给中心类型,资源供给中心在网络中所处结点的 ID 等。
需求点:通常是指需要资源供给中心提供的服务和资源的位置,也对应于网络结点。
最大阻力值:用来限制需求点到资源供给中心的花费。如果需求点到此资源供给中心的花费大于最大阻力值,则该需求点被过滤掉,即该资源供给中心不能服务到此需求点。
资源供给中心类型:包括非中心点,固定中心点和可选中心点。
1. 固定中心点是指网络中已经存在的、已建成的服务设施(扮演资源供给角色);
2. 可选中心点是指可以建立服务设施的资源供给中心,即待建服务设施将从这些可选中心点中选址;
3. 非中心点在分析时不予考虑,在实际中可能是不允许建立这项设施或者已经存在了其他设施。
另外,分析过程中使用的需求点都为网络结点,即除了各种类型的中心点所对应的网络结点,所有网络结点都作为资源需求点参与选址分区分析,如果要排除某部分结点,可以将其设置为障碍点。
是否从中心点分配:从中心点分配,表示资源通过网络传输到需求点;不从中心点分配,表示需求方通过网络前往中心点获得资源。下面通过两个实例来帮助理解:
1. 从中心点开始分配(供给到需求)的例子:
电能是从电站产生,并通过电网传送到客户那里去的。在这里,电站就是网络模型中的中心,因为它可以提供电力供应。电能的客户沿电网的线路(网络模型中的弧段)分布,他们产生了“需求”。在这种情况下,资源是通过网络由供方传输到需要来实现资源分配的。
2. 不从中心点开始分配(需求到供给)的例子:
学校与学生的关系也构成一种在网络中供需分配关系。学校是资源提供方,它负责提供名额供适龄儿童入学。适龄儿童是资源的需求方,他们要求入学。作为需求方的适龄儿童沿街道网络分布,他们产生了对作为供给方的学校的资源--学生名额的需求。
需求点就是网络中的结点,除此,资源供给中心及其类型、最大阻力值,是否从中心点分配等参数均需要用户设置,在下一节中将介绍选址分区的方法以及如何设置有关参数。
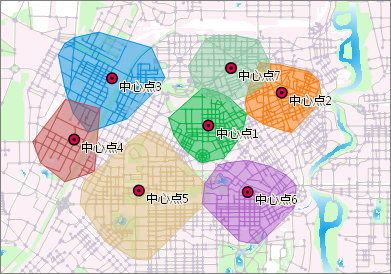
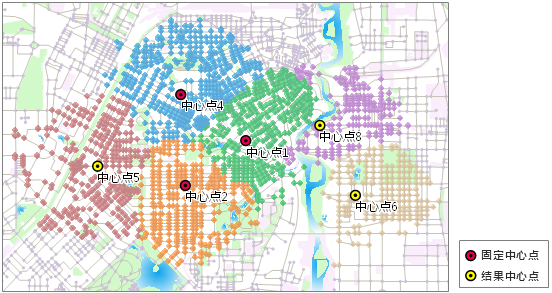
下面通过一个应用实例来加深对选址分区的理解。某个区域目前有 3 所小学,根据需求,拟在该区域内再建立 3 所小学。选择了 9 个地点作为待选地点,将在这些待选点中选择 3 个最佳地点建立新的小学。如图 6-12所示,已有的 3 所小学为固定中心点,7 个候选位置为可选中心点。新建小学要满足的条件为:居民点中的居民步行去学校的时间要在 30 分钟以内。选址分区分析会根据这一条件给出最佳的选址位置,并且圈出每个学校,包括已有的 3 所学校的服务区域。如图 6-13所示,最终序号为 5、6、8 的可选中心点被选为建立新学校的最佳地点。 备注:下面两幅中的网络数据集的所有网络结点被看做是该区域的居民点全部参与选址分区分析,居民点中的居民数目即为该居民点所需服务的数量。
备注:
下面两幅中的网络数据集的所有网络结点被看做是该区域的居民点全部参与选址分区分析,居民点中的居民数目即为该居民点所需服务的数量。
|
图 6-12 用于分析的网络数据集和15个候选中心点 |
|
图 6-13 选址分区分析结果 |
TransportationAnalyst类的FindLocation方法,用于实现选址分区分析。
语法:
public LocationAnalystResult FindLocation(LocationAnalystParameter parameter)
参数说明:
parameter:指定的选址分区分析参数对象。
返回值说明:
选址分区分析结果对象。
该方法需要传入一个LocationAnalystParameter类型的对象作为参数,通过该对象,可以设置选址分区分析的参数信息,包括资源供给中心集合、期望选址的资源供给中心数量、是否从中心点开始分配,以及权重信息等。下面详细介绍选址分区分析参数(LocationAnalystParameter)类的属性,如表 6.9所示:
表 6.9 LocationAnalystParameter类的属性列表
类型 |
名称 |
描述 |
SupplyCenters |
SupplyCenters |
获取或设置资源供给中心集合。该集合是自愿供给中心(SupplyCenter)对象的集合,有关SupplyCenter的介绍详见表 6.10。 |
Int32 |
ExpectedSupplyCenterCount |
获取或设置期望的最终用于建立设施的资源供给中心数量。当输入值为0时,最终设施选址的资源供给中心数量默认为覆盖分析区域内的所需最少的供给中心数。 |
Boolean |
IsFromCenter |
获取或设置是否从资源供给中心开始分配资源。
|
String |
WeightName |
获取或设置权值字段信息的名称,即交通网络分析环境设置中指定的权值字段信息集合对象(WeightFieldInfos 对象)中的某一个权值字段信息对象(WeightFieldInfo 对象)的 Name 属性值。 |
String |
TurnWeightField |
获取或设置转向权值字段,该字段是交通网络分析环境设置中指定的转向权值字段集合(TurnWeightFields)对象中的一员。 |
表 6.10 SupplyCenter类的属性列表
类型 |
名称 |
描述 |
Int32 |
ID |
获取或设置资源供给中心点的 ID。 |
Double |
MaxWeight |
获取或设置资源供给中心的最大耗费(阻值)。单位与选址分区分析参数(LocationAnalystParameter)对象的 WeightName 属性所指定的权值字段信息(WeightFieldInfo)对象的权值字段的单位相同。中心点最大阻值设置越大,表示中心点所提供的资源可影响范围越大。 |
SupplyCenterType |
Type |
获取或设置网络分析中资源供给中心点的类型。
|
选址分区分析返回的结果保存在选址分区分析结果(LocationAnalystResult)对象中,从该对象可以获取资源供给结果数组和需求结果数组,如表 6.11所示:
表 6.11 LocationAnalystResult类的属性列表
类型 |
名称 |
描述 |
SupplyResult[] |
SupplyResults |
获取资源供给结果对象数组。 |
DemandResult[] |
DemandResults |
获取需求结果对象数组。 |
资源供给结果数组(SupplyResults)
资源供给结果数组(SupplyResults)是资源供给结果(SupplyResult)对象的集合,包含了所有资源供给中心的资源供给结果。每一个SupplyResult对象对应一个资源供给中心的供给结果,包括该资源供给中心的ID、类型、最大阻力值、所服务的需求结点的数量、总耗费和平均耗费等信息,详见表 6.12。
表 6.12 SupplyResult类的属性列表
类型 |
名称 |
描述 |
Int32 |
ID |
获取该资源供给中心的 ID。 |
SupplyCenterType |
Type |
获取该资源供给中心的类型。 |
Double |
MaxWeight |
获取该资源供给中心的最大阻力值。单位与选址分区分析参数(LocationAnalystParameter)对象的 WeightName 属性所指定的权值字段信息(WeightFieldInfo)对象的权值字段的单位相同。中心点最大阻值设置越大,表示中心点所提供的资源可影响范围越大。 |
Double |
TotalWeights |
获取总耗费。单位与 LocationAnalystParameter 对象的 WeightName 属性所指定的权值字段信息(WeightFieldInfo)对象的权值字段的单位相同。 当选址分区分析选择从资源供给中心分配资源时,总耗费为从该资源供给中心到其所服务的所有需求结点的耗费的总和;反之,不从资源供给中心分配,则总耗费为该资源供给中心所服务的所有需求结点到该资源供给中心的耗费的总和。 |
Double |
AverageWeight |
获取平均耗费,即总耗费除以需求点数。单位与 LocationAnalystParameter 对象的 WeightName 属性所指定的权值字段信息(WeightFieldInfo)对象的权值字段的单位相同。 |
Int32 |
DemandCount |
获取该资源供给中心所服务的需求结点的数量。 |
需求结果数组(DemandResults)
需求结果数组(DemandResults)是需求结果(DemandResult)对象的集合,包含了所有需求结点的需求结果信息。每一个DemandResult对象对应一个需求结点的需求结果,包括该需求结点的结点ID和为其提供服务的资源供给中心的ID,详见表 6.13。
表 6.13 DemandResult类的属性列表
类型 |
名称 |
描述 |
Int32 |
ID |
获取需求结点的结点 ID。 |
Int32 |
SupplyCenterID |
获取资源供给中心的 ID。 |
物流配送是在网络数据集中,给定M个配送中心、N个配送目的地(M,N为大于零的整数)和一些约束条件,分析得到配送顺序和物流路线,从而优化货物运输路径。
其中约束条件可以有:成本费用、车辆数、车辆负载量、收货时间、是否需要回到中心地等,需要根据实际情况将组合的约束条件都考虑进去。就可以结合配送货物量动态生成线路,匹配最优车型,综合考虑发货、收货时间等情况,生成最佳配送线路。
下面以最基础的约束条件情况进行举例:
某区域现有17个配送目的地,2个配送中心,每个目的地的货物需求量不同,给出每辆运输车辆的负载量,没有时间限制。现需要在此条件下得到物流配送的最优路线。
图中为物流配送结果,红色大一点的圆点代表2个配送中心,其它小一点的圆点代表配送目的地,每个配送中心分析得到的多个线路用不同的颜色标示(线路有重合部分),包括它所负责的配送目的地、配送次序以及配送路线。其中黄色、红色两条线路以1号配送中心点为起始点,蓝色、绿色和紫色线路以2号配送中心点为起始点。
在每一条线路中,从配送中心开始,按照配送目的地上标有的数字为顺序沿着线路依次进行配送,完成后再返回配送中心。每个配送需求点的货物需求量不同,需要保证每条线路上的送货总量在配送车辆负载量的规定限度内。
|
图 6-14 物流配送结果 |
FindVRPPath方法用于实现物流配送分析。
语法:
public VRPAnalystResult findVRPPath(VRPAnalystParameter parameter,VehicleInfo[] vehicleInfos,CenterPointInfo[] centerInfos,DemandPointInfo[] demandInfos)
该接口和之前的物流配送接口findMTSPPath相比,多出了车辆信息、需求量等的设置,可以更充分的满足不同情况下的需求。
参数说明:
parameter:指定的物流配送分析参数对象。
vehicleInfos:车辆信息数组。
centerInfos:中心点信息数组。
demandInfos:需求点信息数组。
返回值说明:
物流配送分析结果对象。
下面介绍物流配送中的4种类型的对象。其中参数描述了物流配送分析过程中相关的要求,用户需要根据自己的实际要求选择和设置参数。
1. VRPAnalystParameter:指定的物流配送分析参数类。可以设置障碍边、障碍点、权值字段信息的名字标识、转向权值字段,还可以对分析结果进行一些设置,即在分析结果中是否包含分析途经的以下内容:结点集合,弧段集合,路由对象集合以及站点集合。
表 6.14展示了物流配送分析VRPAnalystParameter类中几个特有的参数及描述,不再重复表 6.5中交通网络分析参数的共同部分。
表 6.14 VRPAnalystParameter类的方法列表
类型 |
名称 |
描述 |
AnalystType |
AnalystType |
获取或设置物流分析中的分析模式,包括LEASTCOST最小耗费模式(默认)、AVERAGECOST平均耗费模式、AREAANALYST区域分析模式。 |
string |
TimeWeight |
获取或设置时间字段信息的名称。 |
VRPDirectionType |
VRPDirectionType |
获取或设置物流分析路线的类型,也可以称之为车辆的行驶模式。 包括ROUNDROUTE从中心点出发并回到中心点(默认值)、STARTBYCENTER从中心点出发但不回到中心点、ENDBYCENTER不从中心点出发但回到中心点。 |
int |
RouteCount |
获取或设置一次分析中派出车辆数目值。 按要求设置,此分析中以车辆数为前提得到线路数,线路数与实际派出车辆数相同;若不设置此参数,默认派出车辆数不会超过可以提供的车辆总数N(vehicleInfo[N])。 |
区域分析模式(AREAANALYST):使分析结果中每条线路的需求点尽量集中在一个区域。
2. VehicleInfo:车辆信息类。可以设置车辆的最大耗费值、最大负载量等信息。
VehicleInfo[1]:表示所有车辆为同一规格。
VehicleInfo[N]:表示可以提供N辆车。
表 6.15 VehicleInfo类的方法列表
类型 |
名称 |
描述 |
double[] |
LoadWeights |
获取或设置车辆负载量,可以为多维,例如可以同时设置最大承载重量和最大承载体积。要求分析中每一条线路的运输车辆负载量都不超过此值。 |
double |
Cost |
获取或设置车辆的最大耗费值,与WeightName设置的单位一致。 |
Date |
StartTime |
获取或设置车辆最早发车时间。 |
Date |
EndTime |
获取或设置车辆最晚返回时间。 |
Point2D |
SEPoint |
获取或设置物流分析单向路线中的起止点坐标。设置该方法时,路线类型 VRPDirectionType必须为STARTBYCENTER或者ENDBYCENTER,该参数方起作用。 当路线类型为STARTBYCENTER时,该参数表示车辆最终的停靠位置。当路线类型为ENDBYCENTER时,该参数表示车辆最初的起始位置。 |
int |
SEID |
获取或设置物流分析单向路线中的起止结点ID。 |
double |
AreaRatio |
获取或设置物流分析的区域系数。使用在AnalystType中的AREAANALYST方法中。该系数越大,最后结果中线路分配到的点越密集,建议取值范围0到1之间。系数数值根据最远点距离自动取值。 |
3. CenterPointInfo:中心点信息类,存储了中心点的坐标或者结点ID。
表 6.16 CenterPointInfo类的方法列表
类型 |
名称 |
描述 |
int |
CenterID |
获取或设置中心点ID。 |
Point2D |
CenterPoint |
获取或设置中心点坐标。 |
4. demandpointInfo:需求点信息类,存储了需求点的坐标或者结点ID,以及需求点的需求量。
表 6.17 SupplyResult类的方法列表
类型 |
名称 |
描述 |
int |
DemandID |
获取或设置需求点ID。 |
Point2D |
DemandPoint |
获取或设置需求点坐标。 |
double |
Demands |
获取或设置目的地需求量,可以为多维。维度和单位必须和车辆负载(LoadWeights)相同; 若某目的地的需求量过大超过车辆最大负载,分析中会舍弃此点。 |
int |
UnloadTime |
获取或设置卸载货物时间,表示车辆在该点需要停留的时间。单位默认为分钟。 |
Date |
StartTime |
获取或设置到达最早时间,表示车辆到达该点的最早时间点。 |
Date |
EndTime |
获取或设置达到最晚时间,表示车辆到达该点的最晚时间点。 |
通过对车辆、需求点和中心点相关信息的设置,该接口可以根据这些条件来合理划分路线,完成相应的分配任务。
物流配送分析返回的结果保存在物流配送分析结果(VRPAnalystResult)对象中,如表 6.18所示:
表 6.18 VRPAnalystResult类的方法列表
类型 |
名称 |
描述 |
int[][] |
Edges |
获取分析结果的途经弧段集合。数组的一维长度为车辆数,二维元素为各条路径途经弧段的弧段 ID。 |
int[][] |
Nodes |
获取分析结果的途经结点集合。数组的一维长度为车辆数,二维元素为各条路径途经结点的结点 ID。 |
PathGuide[] |
PathGuides |
获取行驶导引集合。 |
GeoLineM[] |
Routes |
获取分析结果的路由对象集合。注意,必须将 VRPAnalystParameter 对象的 setRoutesReturn 方法设置为 true,分析结果中才会包含路由集合,否则为一个空的数组。 |
int[][] |
StopIndexes |
获取站点索引的二维数组。该数组反映了站点在分析后的排列顺序。数组的一维长度为车辆数,二维元素的站点索引。根据不同的分析线路类型VRPDirectionType,该数组的取值意义有所不同。 |
double[][] |
StopWeights |
获取根据站点索引对站点排序后,站点间的花费(权值)。单位与分析参数(VRPAnalystParameter)对象的 setWeightName 方法所指定的权值字段信息(WeightFieldInfo)对象的权值字段的单位相同。 数组一维长度为路径的数量,二维元素为该路径所经过的站点的之间的耗费。 |
java.util.Date[][] |
Times |
获取物流配送每条线路中各配送点出发的时间(最后一个点除外,其表示到达的时间)。 |
int[] |
VehicleIndexs |
获取物流配送中每条线路的车辆索引。 |
double[][] |
VRPDemandValues |
获取物流配送中每条线路的负载量。 |
double[] |
Weights |
获取代表花费的权值数组。单位与分析参数(VRPAnalystParameter)对象的 setWeightName 方法所指定的权值字段信息(WeightFieldInfo)对象的权值字段的单位相同。 |
站点索引(getStopIndexes):数组的一维长度为车辆数,二维元素的站点索引。注意,该索引包含了中心点索引。根据不同的分析线路类型VRPDirectionType,该数组的取值意义有所不同:
1. ROUNDROUTE:数组的一维长度为车辆数,二维元素的站点索引。其中第二维元素的第一个元素和最后一个元素为中心点索引,其他元素为需求点索引。
2. STARTBYCENTER:数组的一维长度为车辆数,二维元素的站点索引。其中第二维元素的第一个元素为中心点索引,其他元素为需求点索引。
3. ENDBYCENTER:数组的一维长度为车辆数,二维元素的站点索引。其中第二维元素的最后一个元素为中心点索引,其他元素为需求点索引。
除了上述内容介绍的交通网络分析功能外,TransportationAnalyst类还提供了三个用于辅助网络分析的方法,包括计算耗费矩阵、更新弧段权值和更新转向结点权值。下面分别对这个三个方法进行介绍。注意,这三个方法也必须在加载网络模型(即调用Load方法)之后调用。
耗费是指从网络上某个结点(或坐标点)到达另一个结点(或坐标点)的最小耗费,也就是两点间最佳路径的耗费。耗费矩阵则是由给定的N个结点(或坐标点)两两间的耗费构成的矩阵。TransportationAnalyst类的ComputeWeightMatrix方法用于计算给定点的耗费矩阵。
语法:
public Double[,] ComputeWeightMatrix(TransportationAnalystParameter parameter)
参数说明:
parameter:指定的交通网络分析参数对象。
返回值说明:
耗费矩阵。
待计算耗费矩阵的点,通过TransportationAnalystParameter类型的参数parameter指定,即通过TransportationAnalystParameter对象的Node属性指定结点集合,或者通过该对象的Points属性指定坐标点集合,但注意二者互斥,如果同时设置,则只有分析前最后的设置有效。例如,先指定了结点集合,又指定了坐标点集合,然后分析,此时只对坐标点进行分析。
除指定待计算耗费矩阵的点集合外,还可通过TransportationAnalystParameter对象的其他属性设置其他必要参数,如网络数据集及其拓扑关系字段、权值信息等,此外,设置障碍点和障碍边也是有效的。
该方法返回的耗费矩阵是一个等长二维数组,元素的索引与指定的被计算点的索引一致,例如,元素 [1,2] 的值为点集合中索引为 1 的点到索引为 2 的点的最小耗费。注意,计算结果包含点自身到自身的耗费,并且为 0。
TransportationAnalyst类的UpdateEdgeWeight 方法用于对网络模型中的弧段权值进行修改。
语法:
public Double UpdateEdgeWeight(Int32 edgeID, Int32 fromNodeID, Int32 toNodeID, String weightName, double weight)
参数说明:
edgeID:指定的被更新的弧段的弧段 ID。
fromNodeID:指定的被更新的弧段的起始结点 ID。
toNodeID:指定的被更新的弧段的终止结点 ID。
weightName:指定的被更新的权值字段所属的权值字段信息对象的名称,即在交通网络分析环境(TransportationAnalystSetting)中指定的 WeightFieldInfos 对象中相应的 WeightFieldInfo 对象的 Name 属性的值。
weight:指定的权值,即用该值更新旧值。单位与 weightName 指定的权值信息字段对象中权值字段的单位相同。
返回值说明:
成功返回更新前的权值,失败返回 Double.MinValue。
首先,需要明确,该方法用于对加载到内存中的网络模型的弧段权值进行修改,并不会修改网络数据集。因此,该方法提供了对弧段权值进行临时性修改的途经,从而免去修改网络数据集或源数据的弧段权值后需要重新加载网络模型的麻烦。
该方法可以更新弧段的正向权值或反向权值。正向权重是指从弧段的起始结点到达终止结点的花费,反向权值为从弧段的终止结点到达起始结点的花费。因此,指定 fromNodeID 为网络数据集中被更新弧段的起始结点 ID,toNodeID 为该弧段的终止结点 ID,则更新正向权值,反之,指定 fromNodeID 为网络数据集中该弧段的终止结点 ID,toNodeID 为该弧段的起始结点 ID,则更新反向权值。
注意,权值为负数表示弧段在该方向禁止通行。
TransportationAnalyst类的UpdateTurnNodeWeight 方法用于对网络模型中的转向表中的转向权值进行修改。
语法:
public Double UpdateTurnNodeWeight(Int32 nodeID, Int32 fromEdgeID, Int32 toEdgeID, String turnWeightField, double weight)
参数说明:
nodeID:指定的被更新的转向结点的结点 ID。
fromEdgeID:指定的被更新的转向结点的起始弧段 ID。
toEdgeID:指定的被更新的转向结点的终止弧段 ID。
turnWeightField:指定的转向权值字段名称,即在交通网络分析环境(TransportationAnalystSetting)中指定的 TurnWeightFields 中的一个值。
weight:指定的权值,即用该值更新旧值。单位与 turnWeightField 指定的转向权值字段的单位相同。
返回值说明:
成功返回更新前的权值,失败返回 Double.MinValue。
首先,需要明确,该方法用于对加载到内存中的网络模型的转向表的转向权值进行修改,并不会修改转向表。因此,该方法提供了对转向权值进行临时性修改的途经,从而免去修改转向表后需要重新加载网络模型的麻烦。
在一个结点处,可能产生多种转向。转弯的方向通过给定的转向结点的起始弧段 ID 和终止弧段 ID 确定。通过该方法指定对应的起始弧段ID和终止弧段ID,从而修改转向结点处对应的转向权值。注意转向权值为负数表示该转弯方向禁止通行。
有关转向表,请参阅第3章的介绍。