搭建未开启Kerberos认证的Hadoop Yarn集群 |
SuperMap iServer 分布式分析支持使用Hadoop Yarn集群,您可以参照以下流程自行搭建。本章主要介绍如何搭建未开启Kerberos认证的Hadoop Yarn集群。
搭建 Hadoop Yarn集群环境需要配置 Java 环境(JDK 下载地址http://www.oracle.com/technetwork/java/javase/downloads/index-jsp-138363.html#javasejdk,建议使用 JDK 8及以上版本)、配置SSH以及 Hadoop。
本例使用的软件为:
Hadoop安装包:hadoop-2.7.3.tar.gz 存放路径:/home/iserver
JDK安装包:jdk-8u131-linux-x64.tar.gz
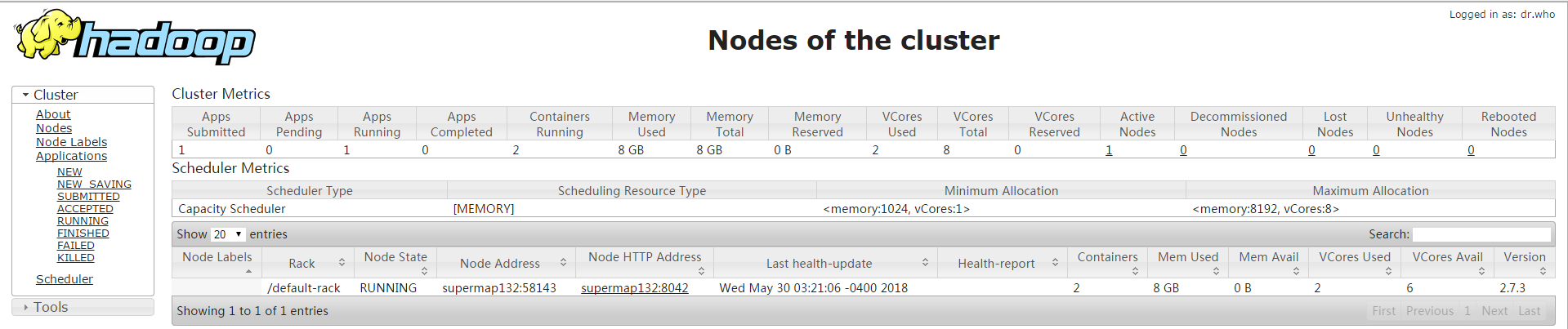
本例主要是在两台ubuntu(内存均为12g)上搭建1个master、1个worker的Hadoop Yarn集群,以下是搭建步骤:
export JAVA_HOME=/home/supermap/java/jdk1.8.0_131
export PATH=${JAVA_HOME}/bin:$PATH
执行source /etc/profile使环境变量生效。
分别在master和worker上执行ssh-keygen -t rsa -P’’(-P表示密码,可以忽略,默认需要三次回车) 执行完命令后 在/home/hdfs/.ssh目录下生成 私钥文件(id_rsa)、公钥文件(id_rsa.pub)。然后分别在master和worker上执行以下命令
ssh-copy-id -i /home/hdfs/.ssh/id_rsa.pub ip
其中,如果在master上执行,则写worker节点对应的ip。在master和worker上执行ssh worker/master,验证是否配置成功。
将一个完整的hadoop包,放在在master的目录中并进行以下配置:
进入/home/supermap/hadoop-2.7.6/etc/hadoop目录
export JAVA_HOME=/home/supermap/java/jdk1.8.0_131
export JAVA_HOME=/home/supermap/java/jdk1.8.0_131
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.112.131</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.112.131:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.112.131:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.112.131:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.112.131:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.112.131:8088</value>
</property>
<!--<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>8192</value>
</property>-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
</configuration>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.112.131:9000</value>
</property>
<!-- <property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>-->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/supermap/hadoop/tmp</value>
<description>Abasefor other temporary directories.</description>
</property>
</configuration>
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>192.168.112.131:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.112.131:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/supermap/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/supermap/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.112.131:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.112.131:19888</value>
</property>
</configuration>
Scp –r /home/supermap/hadoop-2.7.6/etc/hadoop root@worker:/home/supermap/hadoop-2.7.6/etc/hadoop
这样worker就变成yarn集群的一个子节点了,同样在子节点中修改master和slaves文件。 这样就搭建好了一个简单的yarn集群。