接下来以自定义密度聚类工具为例提供了使用示范,以便您能快速理解如何通过 REST API 使用处理自动化服务。
通过iserver服务管理页面,进入处理自动化服务的基本信息页面,点击服务地址(http://localhost:8090/iserver/services/geoprocessing/restjsr)即可进入处理自动化服务的资源页面,查看处理自动化服务根资源下的工具列表,在模型工具下找到自定义工具TownCluster。
如果需要查看已发布模型的资源页面,可以直接在建模页面的模型列表中选中模型,点击鼠标右键在弹出菜单中选择“打开资源页面”。
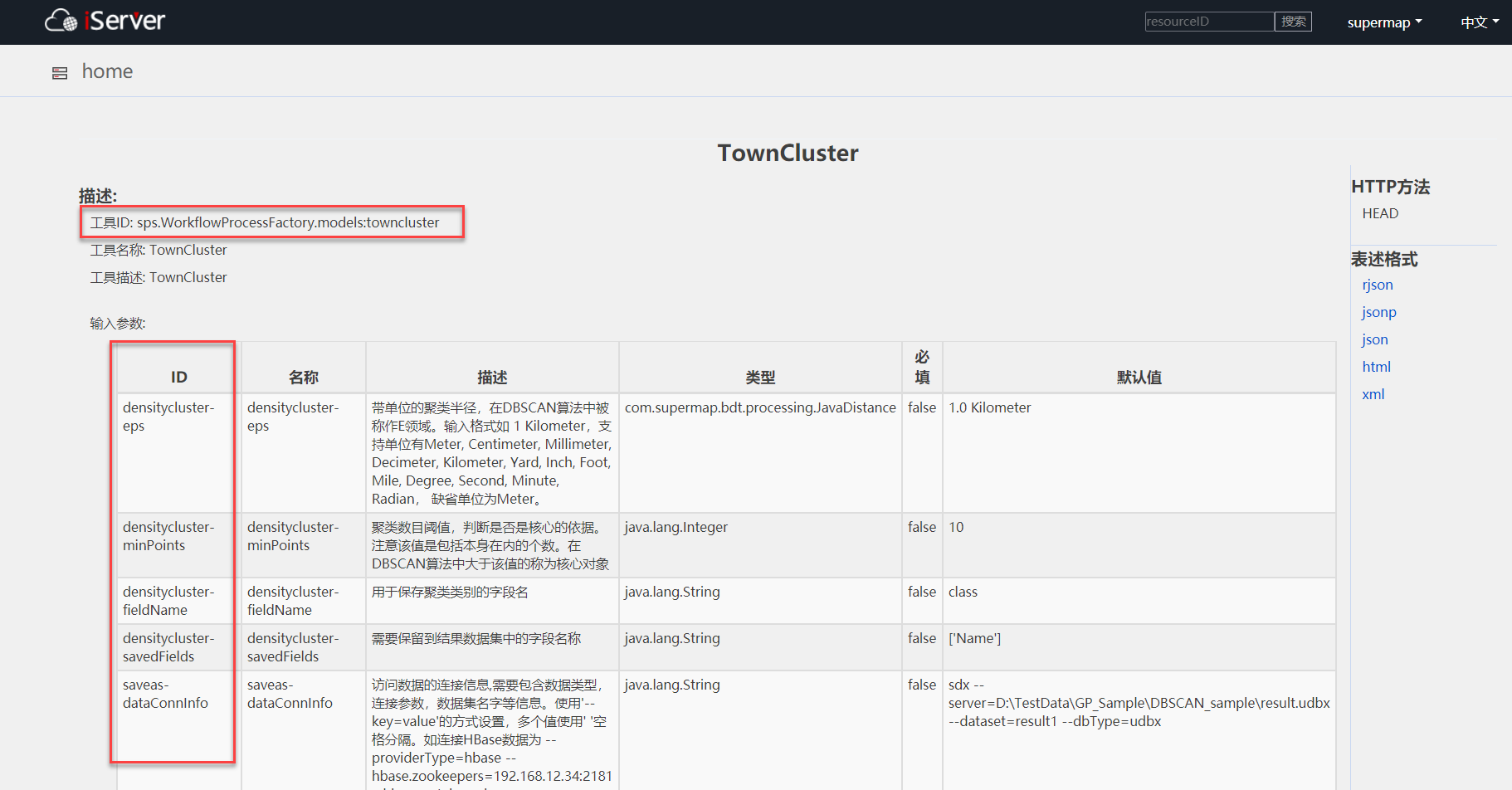
查看TownCluster工具的描述,确定工具ID、需要设置的参数ID等内容,并在iServer中生成令牌(请参考:获取 Token )。
图 TownCluster工具的描述
根据发布的工具ID(sps.WorkflowProcessFactory.models:towncluster)、工具的参数ID以及要设置的参数值、生成的令牌,构建异步执行处理自动化工具POST请求URI如下:
http://172.16.16.8:8090/iserver/services/geoprocessing/restjsr/gp/v2/sps.WorkflowProcessFactory.models:towncluster/jobs?token=OCtW1D34XoGM2xmxSUWfoTrWNbNlgfuVoQi8w4Tqejfh_7apnBAe6pt4zPWw1ClHtC4_LHNomodhp2vHMN8G-A..
根据发布的工具的参数ID以及要设置的参数值,构建如下POST请求参数(由于发布模型时勾选了保留参数,在此可只设置需要调整的参数,其余的参数使用发布时保留的参数)。另外,为了保障数据传输过程的安全性,可以通过在请求体中添加"secretKey"秘钥参数来对数据连接信息中的敏感信息进行加密。在后续获取任务结果信息时,同样需要添加该秘钥参数进行解密操作。如果加密和解密所用的秘钥一致,直接返回原文,否则返回加密后的连接信息。:
{
"parameter": {
"densitycluster-savedFields":["County","NAME"],
"densitycluster-eps":"15.0 Kilometer",
"saveas-dataConnInfo":"--host=172.16.112.9 --port=5432 --database=postgis --user=postgres --passwd=●●●●●●● --dataset=Town_15km --dbType=PGGIS --providerType=jdbc"
},
"secretKey":"1234567890qwerty",
"environments":[
{
"master":"spark://172.16.16.8:7077",
"appName":"Geoprocessing",
"settings":["spark.cores.max=8","spark.driver.host=192.168.17.43","spark.executor.memory=32g"]
}
]
}
对模型构建器中已发布的自定义密度聚类工具的URI执行POST请求
返回JSON格式的任务状态信息如下:
{"jobID":"gp-20200902-162021-B96D5","status":"started"}
通过异步执行的POST请求,您在返回的状态信息中可以得到此次执行的处理自动化任务ID(gp-20200902-162021-B96D5),根据这个任务ID和处理自动化工具ID,您可以通过GET请求查看相关的任务信息和结果。
以下为该处理自动化任务信息的GET请求URI:
http://172.16.16.8:8090/iserver/services/geoprocessing/restjsr/gp/v2/sps.WorkflowProcessFactory.models:towncluster/jobs/gp-20200902-162021-B96D5.rjson?token=OCtW1D34XoGM2xmxSUWfoTrWNbNlgfuVoQi8w4Tqejfh_7apnBAe6pt4zPWw1ClHtC4_LHNomodhp2vHMN8G-A..
得到的处理自动化任务信息如下:
{
"jobID": "gp-20200902-162021-B96D5",
"processID": "sps.WorkflowProcessFactory.models:towncluster",
"messages": {
"result": "{"saveas-isSuccessful":"--host=nm6X2rjKIcH9fgv7VOdlNg== --port=5432 --database=postgis --user=dOG1xePrLDVeMPzoGsSiPA== --passwd=1kVkKc0xVXTU89C081Kb9w== --dataset=Town_15km --dbtype=PGGIS --providerType=jdbc"}",
"processMethodStatus": {
"读取矢量数据": "FINISHED",
"密度聚类": "FINISHED",
"保存矢量数据": "FINISHED"
},
"parameter": "{"densitycluster-savedFields":["County","NAME"],"densitycluster-eps":"15.0 Kilometer","saveas-dataConnInfo":"--providerType=dsf --path=/home/dsfdata"}"
},
"processTitle": "TownCluster",
"state": {
"formatStartTime": "2020-09-02 16:20:21",
"errorStackTrace": null,
"success": true,
"startTime": 1599034821996,
"formatEndTime": "2020-09-02 16:20:22",
"endTime": 1599034822335,
"runState": "FINISHED",
"errorMsg": null,
"elapsedTime": 0
}
}
以下为该处理自动化任务结果的GET请求URI,在URL中带上与执行请求体中相同的"secretKey"密钥参数,将解密数据连接信息返回原文:
http://172.16.16.8:8090/iserver/services/geoprocessing/restjsr/gp/v2/sps.WorkflowProcessFactory.models:towncluster/jobs/gp-20200902-162021-B96D5/results?token=OCtW1D34XoGM2xmxSUWfoTrWNbNlgfuVoQi8w4Tqejfh_7apnBAe6pt4zPWw1ClHtC4_LHNomodhp2vHMN8G-A..&secretKey=1234567890qwerty
得到的处理自动化任务结果如下:
{"saveas-isSuccessful":"--host=172.16.112.9 --port=5432 --database=postgis --user=postgres --passwd=●●●●●●● --dataset=Town_15km --dbType=PGGIS --providerType=jdbc"}
http://172.16.16.8:8090/iserver/services/geoprocessing/restjsr/gp/v2/sps.WorkflowProcessFactory.models:towncluster/execute?parameter={"densitycluster-savedFields":"['M_unite','place_name']","saveas-dataConnInfo":"--providerType=hbase --hbase.zookeepers=172.16.16.8:2181 --hbase.catalog=demo --dataset=Town_15km","densitycluster-eps":"15.0 Kilometer"}&environment=[{"type":"BDT_Spark_Environment","master":"spark://172.16.16.8:7077","appName":"Geoprocessing","settings":["spark.cores.max=8","spark.driver.host=192.168.17.43","spark.executor.memory=32g"]}]&token=OCtW1D34XoGM2xmxSUWfoTrWNbNlgfuVoQi8w4Tqejfh_7apnBAe6pt4zPWw1ClHtC4_LHNomodhp2vHMN8G-A..
对模型构建器中已发布的自定义密度聚类工具的URI执行GET请求,即可对该地区的城镇进行密度聚类分析。得到的处理自动化任务结果如下:
{"saveas-isSuccessful":"--providerType=dsf --path=/home/dsfdata"}
同步执行处理自动化工具的请求URI对格式要求较高,请避免在URI中使用多余的空格和换行,可将URI拷贝至浏览器中进行验证。若参数中的某些特殊字符需要进行编码,可使用编码工具进行处理。
相关 REST API 介绍请参考geoprocessing。