要为模型中的工具指定参数设置,需要通过鼠标左键点击输入节点,此时在页面右侧的参数栏会出现参数填写注释,根据注释要求输入符合格式的参数值即可。当前工具所有必填参数填写完毕后,工具的功能节点框线会由灰色变为蓝色,由此,您可根据节点的外框颜色情况快速检查模型参数填写情况。
图 输入节点参数设置
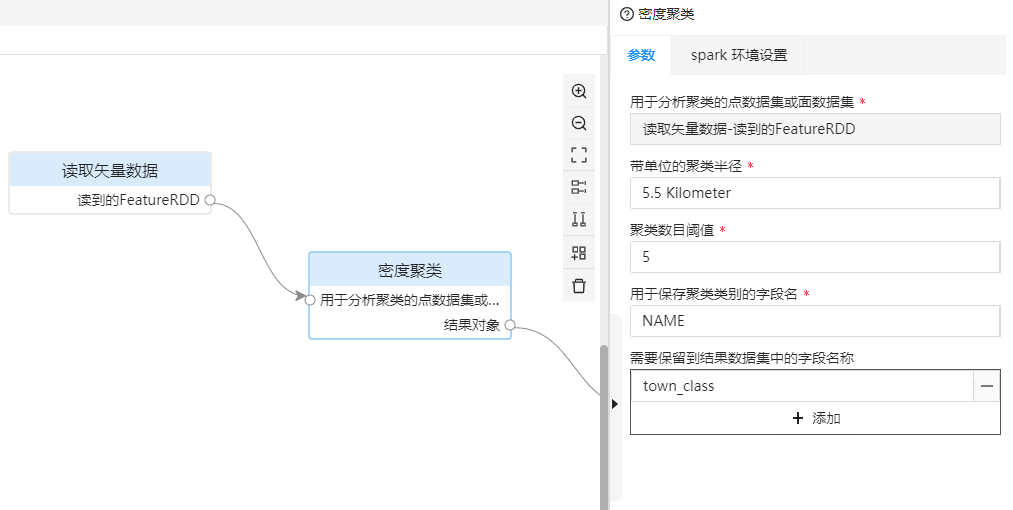
进行城镇密度聚类分析,需要填写的参数示例如下:
| 工具名 | 参数名 | 参数释义 | 值 |
| 读取矢量数据 | 连接信息 | 城镇数据的连接信息,此处示例为存储于HBase中的城镇数据,您可以将示例数据导入Hbase中。 |
--providerType=hbase --hbase.zookeepers=172.16.16.8:2181 --hbase.catalog=demo --dataset=Town_P |
| 密度聚类 | 带单位的聚类半径 | 进行城镇密度聚类分析的聚类半径。 | 5.5 Kilometer |
| 密度聚类 | 密度聚类阈值 | 进行城镇密度聚类分析的聚类数目阈值,用于判断是否为核心。 | 5 |
| 密度聚类 | 用于保存聚类类别的字段名 | 用于保存城镇聚类结果的字段名称。 | town_class |
| 密度聚类 | 需要保留到结果数据集中的字段名称 | 城镇数据中需要保留的结果字段名称,在这里只保存城镇的名称。 | NAME |
| 保存矢量数据 | 连接信息 | 保存城镇聚类分析结果的连接信息。 | --providerType=hbase --hbase.zookeepers=172.16.16.8:2181 --hbase.catalog=demo --dataset=Town_c |
使用Apache Spark进行空间大数据分布式分析,在运行模型前可以通过以下两种方式配置集群环境参数:
配置单模型集群环境参数
处理自动化服务建模页面中使用大数据工具时,点击工具节点可以在参数面板切换"Spark 环境设置"选项,设置好对应参数,在运行模型时将连接集群并提交处理自动化任务。
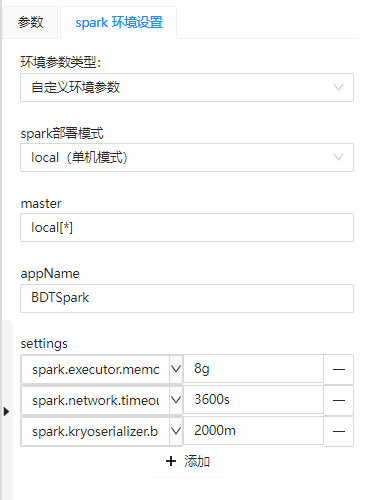
图 环境参数设置
配置全局集群环境参数
为了方便复用集群环境参数, 提供了全局Spark环境参数的配置。具体步骤如下:
1. 在处理自动化服务建模页面,点击左侧菜单栏中的 “环境” 项,进行 Spark全局环境参数的配置;
2. 在环境配置页面,可以点击"添加"按钮来配置环境参数。支持将添加的一组环境参数设置为默认模式,勾选“Spark集群默认部署模式”后,当新增带有大数据工具的模型时,将自动填充该环境参数;
3. 在模型的参数面板中,Spark环境设置新增“环境参数类型”参数,通过下拉菜单可以方便的配置和切换全局环境参数,也可以按需修改默认填充的全局环境参数。
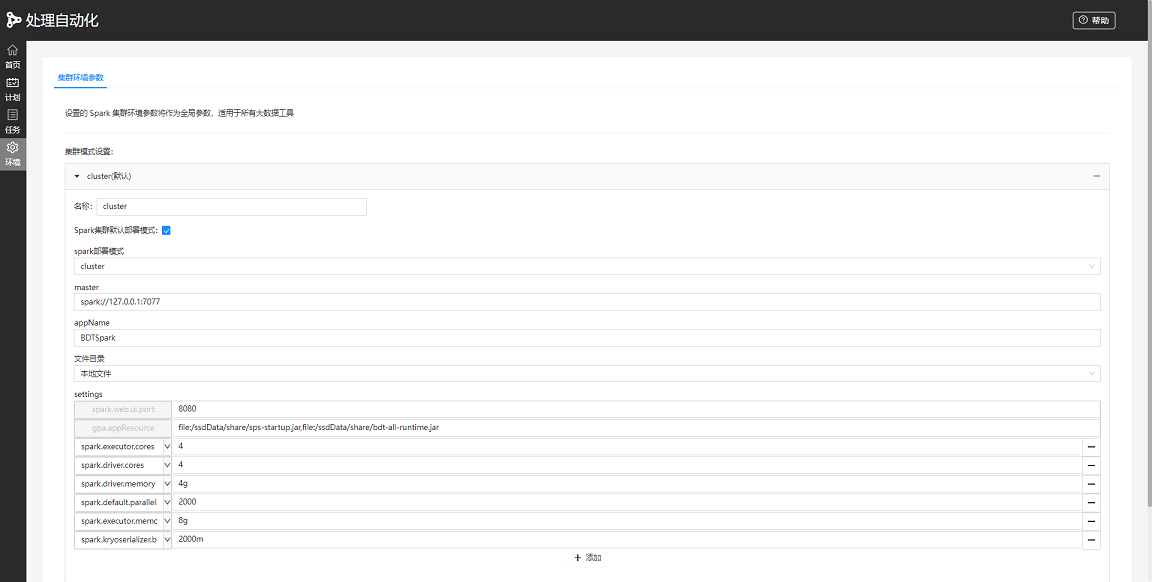
图 全局环境参数设置
集群环境参数主要包括以下四部分:
spark部署模式:包括local,client,cluster。
master:必填参数,集群master地址,如spark://172.16.16.8:7077。
appName:必填参数,应用程序名称,如geoprocessing。
settings:集群配置的参数设置。选填参数。如spark.cores.max=4,spark.executor.memory=16g,spark.driver.host=192.168.17.43。更多参数配置说明请参考:大数据工具的集群环境说明
注:Spark为2.3以上的版本时,Windows的处理自动化服务任务提交至外部集群需要在配置参数中增加spark.driver.host参数设置,参数值为当前应用程序运行机器的IP地址。若当前应用程序所在机器是多网卡,该参数值需要为集群能够访问到的IP。 设置了环境参数,运行模型后即可连接上Spark集群并向集群提交任务,模型使用的数据读取、分析等工具会默认使用该参数连接的集群以及创建的任务。